Gephi is a great tool, but it’s only as good as its input.
The Gephi 8.2 email importer (missing in Gephi 9.*) is lossy, informationally speaking, as I have mentioned before.
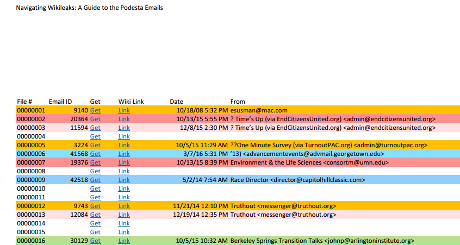
Here’s a sample from the verification results on podesta-release-1-18:
9981 00045326.eml|False|2015-07-24 12:58:16-04:00|Oren Shur |John Podesta , Robby Mook , Joel Benenson , “Margolis, Jim” , Mandy Grunwald , David Binder , Teddy Goff , Jennifer Palmieri , Kristina Schake , Christina Reynolds , Katie Connolly , “Kaye, Anson” , Peter Brodnitz , “Rimel, John” , David Dixon , Rich Davis , Marlon Marshall , Michael Halle , Matt Paul , Elan Kriegel , Jake Sullivan |FW: July IA Poll Results|<168005c7ccb3cbcc0beb3ffaa08a8767@mail.gmail.com>
The Gephi 8.2 mail importer fails to create a node representing an email message.
I propose we cure that failure by taking the last field, here:
168005c7ccb3cbcc0beb3ffaa08a8767@mail.gmail.com
and the next to last field:
FW: July IA Poll Results
and putting them as id and label, respectively in a node list:
168005c7ccb3cbcc0beb3ffaa08a8767@mail.gmail.com; “FW: July IA Poll Results”;
As part of the transformation, we need to remove the < and > signs around the message ID, then add a ; to mark the end of the ID field and put double quote ” “ around the subject to use it as a label. Then close the second field with another ;.
While we are talking about nodes, all the email addresses change from:
Oren Shur
to:
oshur@hillaryclinton.com; “Oren Shur”;
which are ID and label of the node list, respectively.
I could remove the < and > characters as part of the extraction script but will use sed at the command line instead.
Reminder: Always work on a copy of your data, never the original.
Then we need to create an edge list, one that represents the relationships between the email (as node) to the sender and receivers of the email (also nodes). For this first iteration, I’m going to use labels on the edges to distinguish between senders and receivers.
Assuming my first row of the edges file reads:
Source; Target; Role (I did not use “Type” because I suspect that is a controlled term for Gephi.)
Then the first few edges would read:
168005c7ccb3cbcc0beb3ffaa08a8767@mail.gmail.com; oshur@hillaryclinton.com>; from;
168005c7ccb3cbcc0beb3ffaa08a8767@mail.gmail.com; john.podesta@gmail.com>; to;
168005c7ccb3cbcc0beb3ffaa08a8767@mail.gmail.com; re47@hillaryclinton.com; to;
168005c7ccb3cbcc0beb3ffaa08a8767@mail.gmail.com; jbenenson@bsgco.com; to;
168005c7ccb3cbcc0beb3ffaa08a8767@mail.gmail.com; Jim.Margolis@gmmb.com; to;
….
As you can see, this is going to be a “busy” graph! 
Filtering is going to play an important role in exploring this graph, so let’s add nodes that will help with that process.
I propose we add to the node list:
true; True
false; False
as id and labels.
Which means for the edge list we can have:
168005c7ccb3cbcc0beb3ffaa08a8767@mail.gmail.com; true; verify;
Do you have an opinion on the order, source/target for true/false?
Thinking this will enable us to filter nodes that have not been verified or to include only those that have failed verification.
For experimental purposes, I think we need to rework the date field:
2015-07-24 12:58:16-04:00
I would truncate that to:
2015-07-24
and add such truncated dates to the node list:
2015-07-24; 2015-07-24;
as ID and label, respectively.
Then for the edge list:
168005c7ccb3cbcc0beb3ffaa08a8767@mail.gmail.com; 2015-07-24; date;
Reasoning that we can filter to include/exclude nodes based on dates, which if you add enough email boxes, could help visualize the reaction to and propagation of emails.
Even assuming named participants in these emails have “deleted” their inboxes, there are always automatic backups. It’s just a question of persistence before the rest of this network can be fleshed out.
Oh, one last thing. You have probably notice the Wikileaks “ID” that forms part of the filename?
9981 00045326.eml
The first part forms the end of a URL to link to the original post at Wikileaks.
Thus, in this example, 9981 becomes:
https://wikileaks.org/podesta-emails/emailid/9981
The general form being:
https://wikileaks.org/podesta-emails/emailid/(Wikileaks-ID)
For the convenience of readers/users, I want to modify my earlier proposal for the email node list entry from:
168005c7ccb3cbcc0beb3ffaa08a8767@mail.gmail.com; “FW: July IA Poll Results”;
to:
168005c7ccb3cbcc0beb3ffaa08a8767@mail.gmail.com; “FW: July IA Poll Results”; https://wikileaks.org/podesta-emails/emailid/9981;
Where the third field is “link.”
I am eliding over lots of relationships and subjects but I’m not reluctant to throw it all away and start over.
Your investment in a model isn’t lost by tossing the model, you learn something with every model you build.
Scripting underway, a post on that experience and the node/edge lists to follow later today.