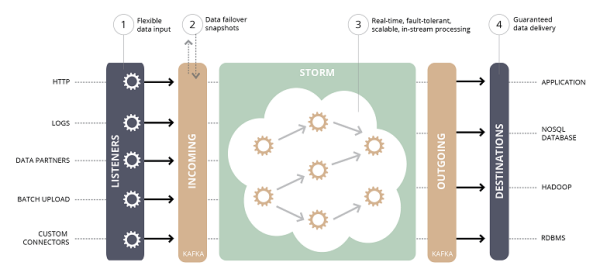
History of Apache Storm and lessons learned by Nathan Marz.
From the post:
Apache Storm recently became a top-level project, marking a huge milestone for the project and for me personally. It’s crazy to think that four years ago Storm was nothing more than an idea in my head, and now it’s a thriving project with a large community used by a ton of companies. In this post I want to look back at how Storm got to this point and the lessons I learned along the way.
The topics I will cover through Storm’s history naturally follow whatever key challenges I had to deal with at those points in time. The first 25% of this post is about how Storm was conceived and initially created, so the main topics covered there are the technical issues I had to figure out to enable the project to exist. The rest of the post is about releasing Storm and establishing it as a widely used project with active user and developer communities. The main topics discussed there are marketing, communication, and community development.
Any successful project requires two things:
- It solves a useful problem
- You are able to convince a significant number of people that your project is the best solution to their problem
What I think many developers fail to understand is that achieving that second condition is as hard and as interesting as building the project itself. I hope this becomes apparent as you read through Storm’s history.
…
All projects are different but the requirements for success:
- It solves a useful problem
- You are able to convince a significant number of people that your project is the best solution to their problem
sound universal to me!
To clarify point #2, “people” means “other people.”
Preaching to a mirror or choir isn’t going to lead to success.
Nor will focusing on “your problem” as opposed to “their problem.”
PS: New Year’s Eve advice – Don’t download large files.  Slower than you want to think. Suspect people on my subnet are streaming football games and/or porno videos, perhaps both (screen within screen).
Slower than you want to think. Suspect people on my subnet are streaming football games and/or porno videos, perhaps both (screen within screen).
I first saw this in a tweet by Bob DuCharme.