SPARQL queries of Beatles recording sessions – Who played what when? by Bob DuCharme.
From the post:
While listening to the song Dear Life on the new Beck album, I wondered who played the piano on the Beatles’ Martha My Dear. A web search found the website Beatles Bible, where the Martha My Dear page showed that it was Paul.
This was not a big surprise, but one pleasant surprise was how that page listed absolutely everyone who played on the song and what they played. For example, a musician named Leon Calvert played both trumpet and flugelhorn. The site’s Beatles’ Songs page links to pages for every song, listing everyone who played on them, with very few exceptions–for example, for giant Phil Spector productions like The Long and Winding Road, it does list all the instruments, but not who played them. On the other hand, for the orchestra on A Day in the Life, it lists the individual names of all 12 violin players, all 4 violists, and the other 25 or so musicians who joined the Fab Four for that.
An especially nice surprise on this website was how syntactically consistent the listings were, leading me to think “with some curl commands, python scripting, and some regular expressions, I could, dare I say it, convert all these listings to an RDF database of everyone who played on everything, then do some really cool SPARQL queries!”
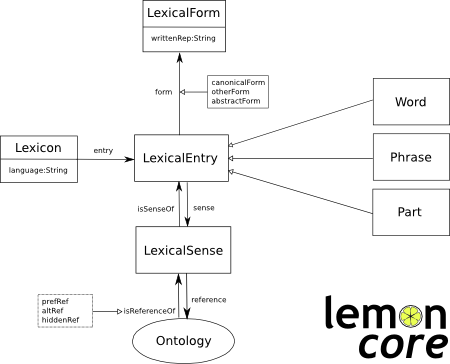
So I did, and the RDF is available in the file BeatlesMusicians.ttl. The great part about having this is the ability to query across the songs to find out things such as how many different people played a given instrument on Beatles recordings or what songs a given person may have played on, regardless of instrument. In a pop music geek kind of way, it’s been kind of exciting to think that I could ask and answer questions about the Beatles that may have never been answered before.
…
Will the continuing popularity of the Beatles drive interest in SPARQL? Hard to say but DuCharme gives it a hard push in this post. It will certainly appeal to Beatles devotees.
Is it coincidence that DuCharme posted this on November 19, 2017, the same day as the reported death of Charles Mason? (cf. Helter Skelter)
There’s a logical extension to DuCharme’s RDF file, Charles Mason, the Mason family and music of that era.
Many foolish things were said about rock-n-rock in the ’60’s that are now being repeated about social media and terrorists. Same rant, same lack of evidence, same intolerance, same ineffectual measures against it. Not only can elders not learn from the past, they can’t wait to repeat it.
Be inventive! Learn from past mistakes so you can make new ones in the future!