From the webpage:
Search NASA Earth Science data by keyword and filter by time or space.
After choosing tour:
Keyword Search
Here you can enter search terms to find relevant data. Search terms can be science terms, instrument names, or even collection IDs. Let’s start by searching for Snow Cover NRT to find near real-time snow cover data. Type Snow Cover NRT in the keywords box and press Enter.
Which returns a screen in three sections, left to right: Browse Collections, 21 Matching Collections (Add collections to your project to compare and retrieve their data), and the third section displays a world map (navigate by grabbing the view)
Under Browse Collections:
In addition to searching for keywords, you can narrow your search through this list of terms. Click Platform to expand the list of platforms (still in a tour box)
Next step:
Now click Terra to select the Terra satellite.
Comment: Wondering how I will know which “platform” or “instrument” to select? There may be more/better documentation but I haven’t seen it yet.
The data follows the Unified Metadata Model (UMM):
NASA’s Common Metadata Repository (CMR) is a high-performance, high-quality repository for earth science metadata records that is designed to handle metadata at the Concept level. Collections and Granules are common metadata concepts in the Earth Observation (EO) world, but this can be extended out to Visualizations, Parameters, Documentation, Services, and more. The CMR metadata records are supplied by a diverse array of data providers, using a variety of supported metadata standards, including:
Initially, designers of the CMR considered standardizing all CMR metadata to a single, interoperable metadata format – ISO 19115. However, NASA decided to continue supporting multiple metadata standards in the CMR — in response to concerns expressed by the data provider community over the expense involved in converting existing metadata systems to systems capable of generating ISO 19115. In order to continue supporting multiple metadata standards, NASA designed a method to easily translate from one supported standard to another and constructed a model to support the process. Thus, the Unified Metadata Model (UMM) for EOSDIS metadata was born as part of the EOSDIS Metadata Architecture Studies (MAS I and II) conducted between 2012 and 2013.
…
What is the UMM?
The UMM is an extensible metadata model which provides a ‘Rosetta stone’ or cross-walk for mapping between CMR-supported metadata standards. Rather than create mappings from each CMR-supported metadata standard to each other, each standard is mapped centrally to the UMM model, thus reducing the number of translations required from n x (n-1) to 2n.

Here the mapping graphic:
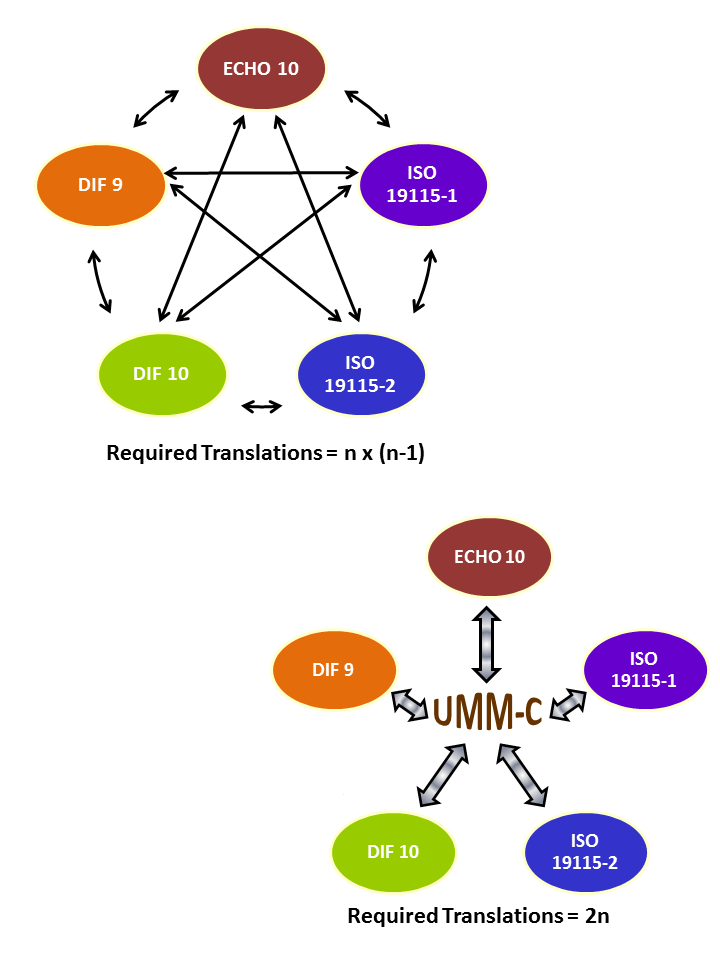
Granting profiles don’t make the basis for mappings explicit, but the mappings have the same impact post mapping as a topic map would post merging.
The site could use better documentation for the interface and data, at least in the view of this non-expert in the area.
Thoughts on documentation for the interface or making the mapping more robust via use of a topic map?
I first saw this in a tweet by Kirk Borne.
*Smells Like A Topic Map – Sorry, culture bound reference to a routine on the first Cheech & Chong album. No explanation would do it justice.