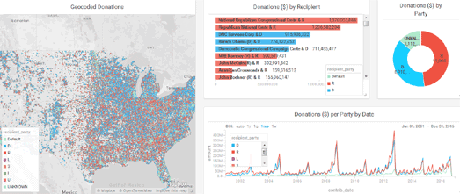
Fast and Flexible Query Analysis at MapD with Apache Calcite by Alex Şuhan.
From the post:
After evaluating a few other options, we decided for Apache Calcite, an incubation stage project at the time. It takes SQL queries and generates extended relational algebra, using a highly configurable cost-based optimizer. Several projects use Calcite already for SQL parsing and query optimization.
One of the main strengths of Calcite is its highly modular structure, which allows for multiple integration points and creative uses. It offers a relational algebra builder, which makes moving to a different SQL parser (or adding a non-SQL frontend) feasible.
In our product, we need runtime functions which are not recognized by Calcite by default. For example, trigonometric functions are necessary for on-the-fly geo projections used for point map rendering. Fortunately, Calcite allows specifying such functions and they become first-class citizens, with proper type checking in place.
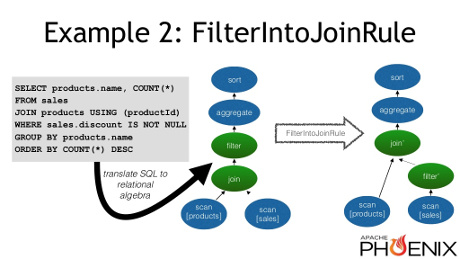
Calcite also includes a highly capable and flexible cost-based optimizer, which can apply high-level transformations to the relational algebra based on query patterns and statistics. For example, it can push part of a filter through a join in order to reduce the size of the input, like the following figure shows:
You can find this example and more about the cost-based optimizer in Calcite in this presentation on using it in the Apache Phoenix project. Such optimizations complement the low-level optimizations we do ourselves to achieve great speed improvements.
Relational algebra example
Let’s take a simple query:SELECT A.x, COUNT(*) FROM test JOIN B ON A.x = B.x WHERE A.y > 41 GROUP BY A.x;and analyze the relational algebra generated for it.In Calcite relational algebra, there are a few main node types, corresponding to the theoretical extended relational algebra model: Scan, Filter, Project, Aggregate and Join. Each type of node, except Scan, has one or more (in the case of Join) inputs and its output can become the input of another node. The graph of nodes connected by data flow relationships is a
directed acyclic graph (abbreviated as “DAG”). For our query, Calcite outputs the following DAG:
The
Scannodes have no inputs and output all the rows and the columns in tablesAandB, respectively. TheJoinnode specifies the join condition (in our caseA.x = B.x) and its output contains the columns inAandBconcatenated. TheFilternode only allows the rows which pass the specified condition and its output preserves all columns of input. TheProjectnode only preserves the specified expressions as columns in the output. Finally, the Aggregate specifies the group by expressions and aggregates.The physical implementation of the nodes is up to the system using Calcite as a frontend. Nothing in the
Joinnode mandates a certain implementation of the join operation (equijoin in our case). Indeed, using a condition which can’t be implemented as a hash join, likeA.x < B.x, would only be reflected by the condition in theFilternode.…

You’re not MapD today but that’s no excuse for poor query performance.
Besides, learning Apache Calcite will increase your attractiveness as data and queries on it become more complex.
I haven’t read all the documentation but the “metadata” in Apache Calcite is as flat as any you will find.
Which means integration of different data sources is either luck of the draw or you asked someone the “meaning” of the metadata.
The tutorial has this example:

The column header “GENDER” for example appears to presume the common male/female distinction. But without further exploration of the data set, there could be other genders encoded in that field as well.
If “GENDER” seems too easy, what would you say about “NAME,” bearing in mind that Japanese family names are written first and given names written second. How would those appear under “NAME?”
Apologies! My screen shot missed field “S.”
I have utterly no idea what “S” may or may not represent as a field header. Do you?
If the obviousness of field headers fails with “GENDER” and “NAME,” what do you suspect will happen with less “obvious” field headers?
How successful will merging of data be?
Where would you add subject identity information and how would you associate it with data processed by Apache Calcite?