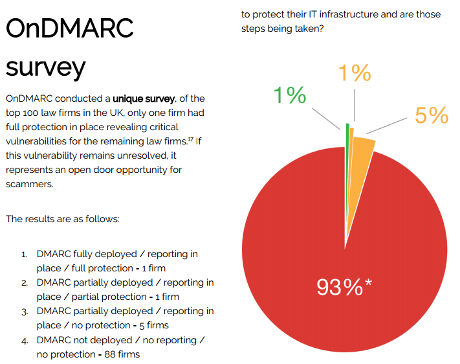
While some stuff runs in the background, a quick tip on parsing email with Python.
I got the following error message from Python:
Traceback (most recent call last):
File “test-clinton-script-31Oct2016.py”, line 20, in
date = dateutil.parser.parse(msg[‘date’])
File “/usr/lib/python2.7/dist-packages/dateutil/parser.py”, line 697, in parse
return DEFAULTPARSER.parse(timestr, **kwargs)
File “/usr/lib/python2.7/dist-packages/dateutil/parser.py”, line 301, in parse
res = self._parse(timestr, **kwargs)
File “/usr/lib/python2.7/dist-packages/dateutil/parser.py”, line 349, in _parse
l = _timelex.split(timestr)
File “/usr/lib/python2.7/dist-packages/dateutil/parser.py”, line 143, in split
return list(cls(s))
File “/usr/lib/python2.7/dist-packages/dateutil/parser.py”, line 137, in next
token = self.get_token()
File “/usr/lib/python2.7/dist-packages/dateutil/parser.py”, line 68, in get_token
nextchar = self.instream.read(1)
AttributeError: ‘NoneType’ object has no attribute ‘read’
I have edited the email header in question but it reproduces the original error:
Delivered-To: john.podesta@gmail.com
Received: by 10.142.49.14 with SMTP id w14cs34683wfw;
Wed, 5 Nov 2008 08:11:39 -0800 (PST)
Received: by 10.114.144.1 with SMTP id r1mr728791wad.136.1225901498795;
Wed, 05 Nov 2008 08:11:38 -0800 (PST)
Return-Path:
Received: from QMTA09.emeryville.ca.mail.comcast.net (qmta09.emeryville.ca.mail.comcast.net [76.96.30.96])
by mx.google.com with ESMTP id m26si29354pof.3.2008.11.05.08.11.38;
Wed, 05 Nov 2008 08:11:38 -0800 (PST)
Received-SPF: pass (google.com: domain of sewallconroy@comcast.net designates
Received: from OMTA03.emeryville.ca.mail.comcast.net ([76.96.30.27])
by QMTA09.emeryville.ca.mail.comcast.net with comcast
id bUBY1a0010b6N64A9UBeJl; Wed, 05 Nov 2008 16:11:38 +0000
Received: from amailcenter06.comcast.net ([204.127.225.106])
by OMTA03.emeryville.ca.mail.comcast.net with comcast
id bUAV1a00L2JMgtY8PUAV7G; Wed, 05 Nov 2008 16:10:30 +0000
X-Authority-Analysis: v=1.0 c=1 a=1Ht49J2nGmlg0oY3xr8A:9
a=8nxvWDfACCTtBObdks-tTUtrMyYA:4 a=OA_lqj45gZcA:10 a=diNjy0DT58-4uIkuavEA:9
a=e0_VUgpf8QEu0XMU188OmzzKrzoA:4 a=37WNUvjkh6kA:10
Received: from [24.34.75.99] by amailcenter06.comcast.net;
Wed, 05 Nov 2008 16:10:28 +0000
From: sewallconroy@comcast.net
To: “Podesta” , ricesusane@aol.com
CC: “Denis McDonough OFA” ,
djsberg@gmail.com”, marklippert@yahoo.com,
Subject: DOD leadership – immediate attention
Date: Wed, 05 Nov 2008 16:10:28 +0000
Message-Id: <110520081610.3048.4911C574000C2E2100000BE82216
55799697019D02010C04040E990A9C@comcast.net>
X-Mailer: AT&T Message Center Version 1 (Oct 30 2007)
X-Authenticated-Sender: c2V3YWxsY29ucm95QGNvbWNhc3QubmV0
MIME-Version: 1.0
Content-Type: multipart/alternative; boundary=”NextPart_Webmail_9m3u9jl4l_3048_1225901428_0″
–NextPart_Webmail_9m3u9jl4l_3048_1225901428_0
Content-Type: text/plain
Content-Transfer-Encoding: 8bit
I’m comparing “Date” to similar emails and getting no joy.
Absence is hard to notice, but once you know the rule, it’s obvious:
RFC822: Standard for ARPA Internet Text Messages says in part:
3. Lexical Analysis of Messages
3.1 General Description
A message consists of header fields and, optionally, a body. The body is simply a sequence of lines containing ASCII characters. It is separated from the headers by a null line (i.e., a line with nothing preceding the CRLF). (emphasis added)
Yep, the blank line I introduced while removing an errant double-quote on a line by itself, created the start for the body of the message.
Meaning that my Python script failed to find the “Date:” field and returning what someone thought would be a useful error message.
When you get errors parsing emails with Python (and I assume in other languages), check the format of your messages!
RFC822 has an appendix of parsing rules and a few examples.
Suggested listings of the most common email/email header format errors?