Solving Open Source Discovery by Andrew Nesbitt.
From the post:
Today I’m launching Libraries.io, a project that I’ve been working on for the past couple of months.
The intention is to help developers find new open source libraries, modules and frameworks and keep track of ones they depend upon.
The world of open source software depends on a lot of open source libraries. We are standing on the shoulders of giants, which helps us to reach further than we could otherwise.
The problem with platforms like Rubygems and NPM is there are so many libraries, with hundreds of new ones added every day. Trying to find the right library can be overwhelming.
How do you find libraries that help you solve problems? How do you then know which of those libraries are worth using?
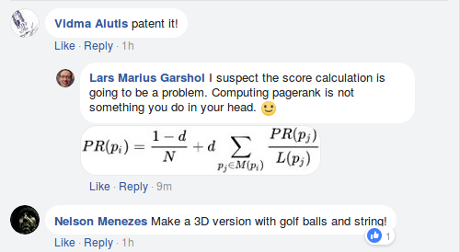
Andrew substitutes dependencies for links in a page rank algorithm and then:
Within Libraries.io I’ve aggregated over 700,000 projects, written in 130 languages from across 22 package managers, including dependencies, releases, license information and source code repository infomation. This results in a rich index of almost every open source library available for use today.
Follow me on Twitter at @teabass and @librariesio for updates. Discussion on Hacker News: https://news.ycombinator.com/item?id=9211084.
Is Libraries.io going to be useful? Yes!
Is Libraries.io a fun way to explore projects? Yes!
Is Libraries.io a great alternative to current source search options? Yes!
Is Libraries.io the solution to open source discovery? Less clear.
I say that because PageRank, whether using hyperlinks or dependencies, results in a lemming view of the world in question.
Wikipedia reports this is an image of a lemming:

I, on the other hand, bear a passing resemblance to this image:

I offer those images as evidence that I am not a lemming! 
The opinions and usages of others can be of interest, but I follow work and people of interest to me, not because they are of interest to others. Otherwise I would be following Lady Gaga on Twitter, for example. To save you the trouble of downloading her forty-five million (45M) followers, I hereby attest that I am not one of them.
Make no mistake, Andrew’s work should be used, followed, supported, improved, but as another view of an important data set, not a solution.
I first saw this in a tweet by Arfon Smith.