It’s more than just overlap: Text As Graph – Refining our notion of what text really is—this time for sure! by Ronald Haentjens Dekker and David J. Birnbaum.
Abstract:
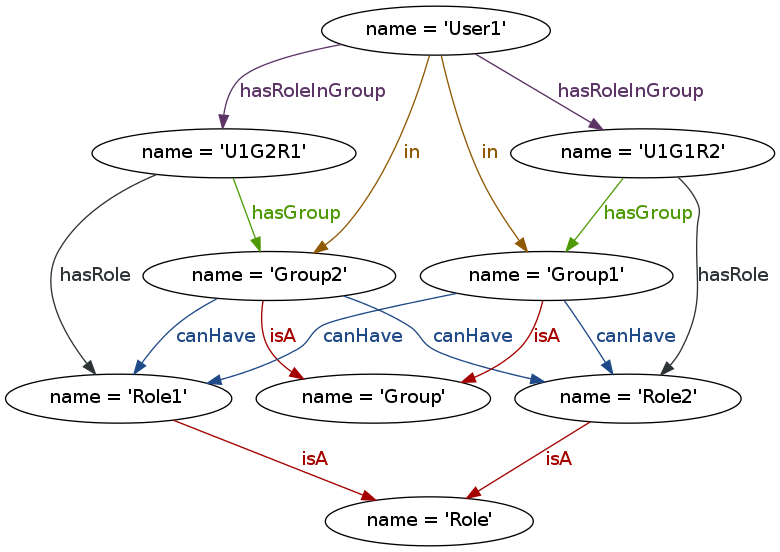
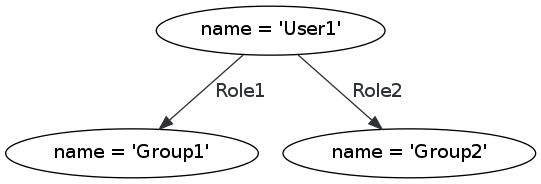
The XML tree paradigm has several well-known limitations for document modeling and processing. Some of these have received a lot of attention (especially overlap), and some have received less (e.g., discontinuity, simultaneity, transposition, white space as crypto-overlap). Many of these have work-arounds, also well known, but—as is implicit in the term “work-around”—these work-arounds have disadvantages. Because they get the job done, however, and because XML has a large user community with diverse levels of technological expertise, it is difficult to overcome inertia and move to a technology that might offer a more comprehensive fit with the full range of document structures with which researchers need to interact both intellectually and programmatically. A high-level analysis of why XML has the limitations it has can enable us to explore how an alternative model of Text as Graph (TAG) might address these types of structures and tasks in a more natural and idiomatic way than is available within an XML paradigm.
Hyperedges, texts and XML, what more could you need? 
This paper merits a deep read and testing by everyone interested in serious text modeling.
You can’t read the text but here is a hypergraph visualization of an excerpt from Lewis Carroll’s “The hunting of the Snark:”
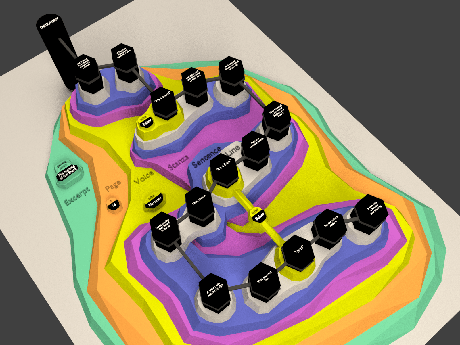
The New Testament, the Hebrew Bible, to say nothing of the Rabbinic commentaries on the Hebrew Bible and centuries of commentary on other texts could profit from this approach.
Put your text to the test and share how to advance this technique!