President Obama has issued new rules for sharing information under Executive Order 12333, with the ungainly title: (U) Procedures for the Availability or Dissemination of Raw Signals Intelligence Information by the National Security Agency Under Section 2.3 of Executive Order 12333 (Raw SIGINT Availability Procedures).
Kate Tummarello, in Obama Expands Surveillance Powers On His Way Out by Kate Tummarello, sees a threat to “innocent persons:”
With mere days left before President-elect Donald Trump takes the White House, President Barack Obama’s administration just finalized rules to make it easier for the nation’s intelligence agencies to share unfiltered information about innocent people.
New rules issued by the Obama administration under Executive Order 12333 will let the NSA—which collects information under that authority with little oversight, transparency, or concern for privacy—share the raw streams of communications it intercepts directly with agencies including the FBI, the DEA, and the Department of Homeland Security, according to a report today by the New York Times.
That’s a huge and troubling shift in the way those intelligence agencies receive information collected by the NSA. Domestic agencies like the FBI are subject to more privacy protections, including warrant requirements. Previously, the NSA shared data with these agencies only after it had screened the data, filtering out unnecessary personal information, including about innocent people whose communications were swept up the NSA’s massive surveillance operations.
As the New York Times put it, with the new rules, the government claims to be “reducing the risk that the N.S.A. will fail to recognize that a piece of information would be valuable to another agency, but increasing the risk that officials will see private information about innocent people.”
…
All of which is true, but the new rules have other impacts as well.
Who is an “IC element?”
The new rules make numerous references to an “IC element,” but comes up short in defining them:
L. (U) IC element is as defined in section 3.5(h) of E.O. 12333.
(emphasis in original)
Great.
Searching for E.O. 12333 isn’t enough. You need Executive Order 12333 United States Intelligence Activities (As amended by Executive Orders 13284 (2003), 13355 (2004) and 13470 (2008)). The National Archives version of Executive Order 12333 is not amended and hence is misleading.
From the amended E.0. 12333:
3.5 (h) Intelligence Community and elements of the Intelligence Community
refers to:
(1) The Office of the Director of National Intelligence;
(2) The Central Intelligence Agency;
(3) The National Security Agency;
(4) The Defense Intelligence Agency;
(5) The National Geospatial-Intelligence Agency;
(6) The National Reconnaissance Office;
(7) The other offices within the Department of Defense for the collection of
specialized national foreign intelligence through reconnaissance programs;
(8) The intelligence and counterintelligence elements of the Army, the Navy,
the Air Force, and the Marine Corps;
(9) The intelligence elements of the Federal Bureau of Investigation;
(10) The Office of National Security Intelligence of the Drug Enforcement
Administration;
(11) The Office of Intelligence and Counterintelligence of the Department
of Energy;
(12) The Bureau of Intelligence and Research of the Department of State;
(13) The Office of Intelligence and Analysis of the Department of the Treasury;
(14) The Office of Intelligence and Analysis of the Department of Homeland
Security;
(15) The intelligence and counterintelligence elements of the Coast Guard; and
(16) Such other elements of any department or agency as may be designated by
the President, or designated jointly by the Director and the head of the
department or agency concerned, as an element of the Intelligence Community.
The Office of the Director of National Intelligence has an incomplete list of IC elements:
I say “incomplete” because from E.O. 12333, it is missing (with original numbers for reference):
...
(7) The other offices within the Department of Defense for the collection of
specialized national foreign intelligence through reconnaissance programs;
(8) The intelligence and counterintelligence elements of ..., and the
Marine Corps;
...
(16) Such other elements of any department or agency as may be designated by
the President, or designated jointly by the Director and the head of the
department or agency concerned, as an element of the Intelligence Community.
Under #7 and #16, there are other IC elements that are unnamed and unlisted by the Office of the DOI. I suspect the Marines were omitted for stylistic reasons.
Where to Find Raw SIGINT?
Identified IC elements are important because the potential presence of “Raw SIGINT,” beyond the NSA, has increased their value as targets.
P. (U) Raw SIGINT is any SIGINT and associated data that has not been evaluated for foreign intelligence purposes and/or minimized.
… (emphasis in original, from the new rules.)
Tummarello is justly concerned about “innocent people” but there are less than innocent people, any number of appointed/elected official or barons of industry who may be captured on the flypaper of raw SIGINT.
Happy hunting!
PS:
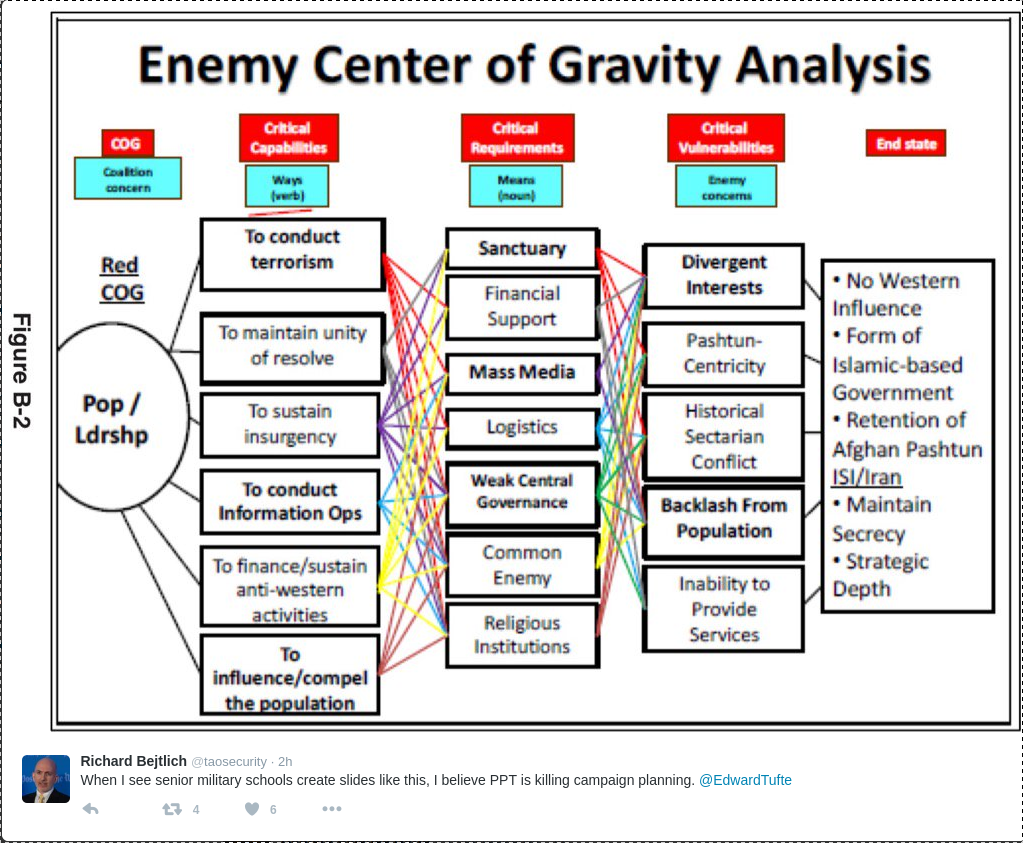
Warning: It’s very bad OPSEC to keep a trophy chart on your wall. 

You will, despite this warning, but I had to try.
The original image is here at Wikipedia.