Krishnan Subramanian’s Modern Enterprise: Slaying the Silos with Data Virtualization keeps coming up in my Twitter feed.
In speaking of breaking down data silos, Krishnan says:
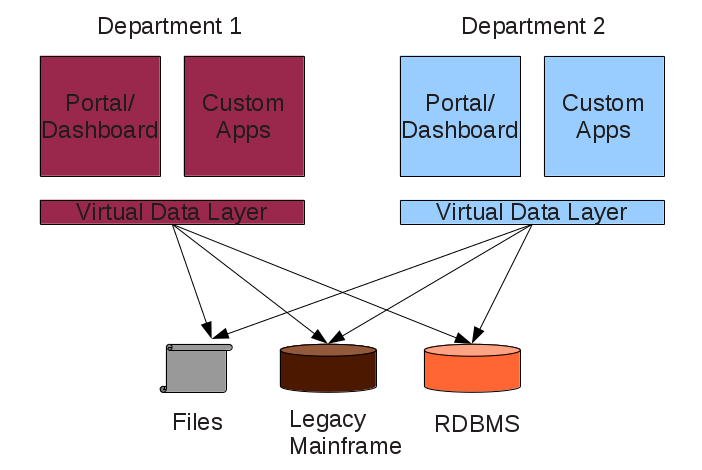
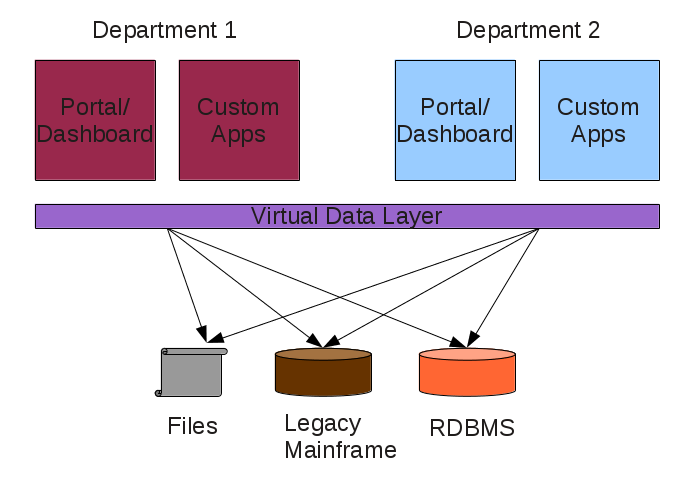
A much better approach to solving this problem is abstraction through data virtualization. It is a powerful tool, well suited for the loose coupling approach prescribed by the Modern Enterprise Model. Data virtualization helps applications retrieve and manipulate data without needing to know technical details about each data store. when implemented, organizational data can be easily accessed using a simple REST API.
Data Virtualization (or an abstracted Database as a Service) plugs into the Modern Enterprise Platform as a higher-order layer, offering the following advantages:
- Better business decisions due to organization wide accessibility of all data
- Higher organizational agility
- Loosely coupled services making future proofing easier
- Lower cost
I find that troubling because there is no mention of data integration.
In fact, in more balanced coverage of data virtualization, which recites the same advantages as Krishnan, we read:
For some reason there are those who sell virtualization software and cloud computing enablement platforms who imply that data integration is something that comes along for the ride. However, nothing gets less complex and data integration still needs to occur between the virtualized data stores as if they existed on their own machines. They are still storing data in different physical data structures, and the data must be moved or copied, and the difference with the physical data structures dealt with, as well as data quality, data integrity, data validation, data cleaning, etc. (The Pros and Cons of Data Virtualization)
Krishnan begins his post:
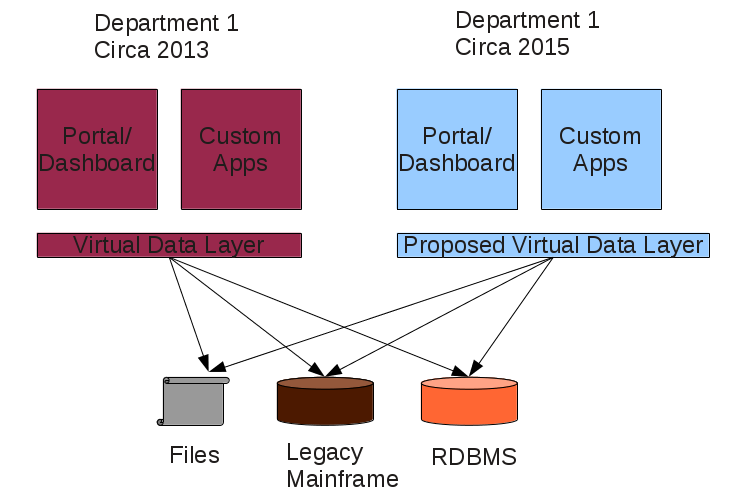
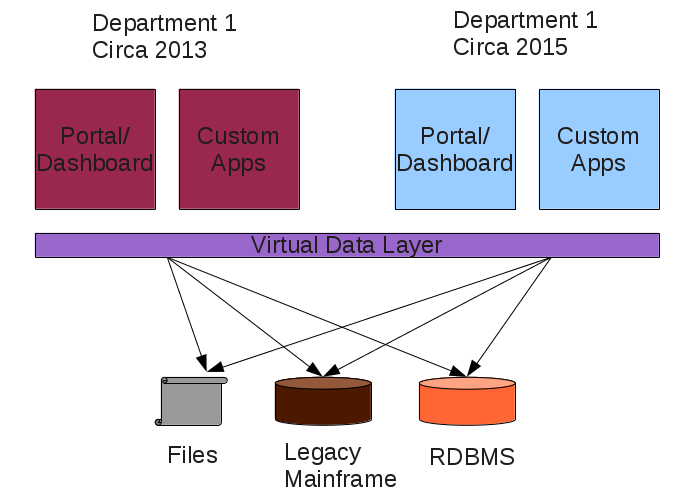
There’s a belief that cloud computing breaks down silos inside enterprises. Yes, the use of cloud and DevOps breaks down organizational silos between different teams but it only solves part of the problem. The bigger problem is silos between data sources. Data silos, as I would like to refer the problem, is the biggest bottlenecks enterprises face as they try to modernize their IT infrastructure. As I advocate the Modern Enterprise Model, many people ask me what problems they’ll face if they embrace it. Today I’ll do a quick post to address this question at a more conceptual level, without getting into the details.
If data silos are the biggest bottleneck enterprises face, why is the means to address that, data integration, a detail?
Every hand waving approach to data integration fuels unrealistic expectations, even among people who should know better.
There are no free lunches and there are no free avenues for data integration.