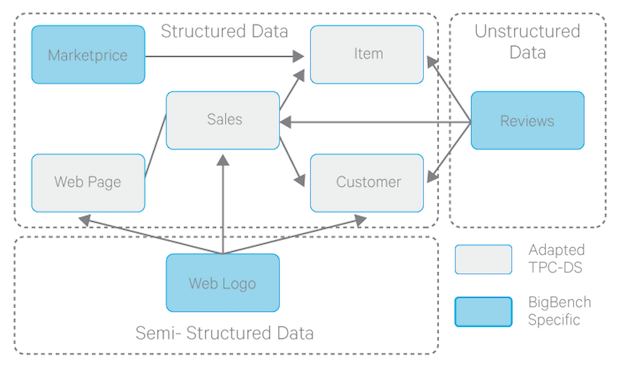
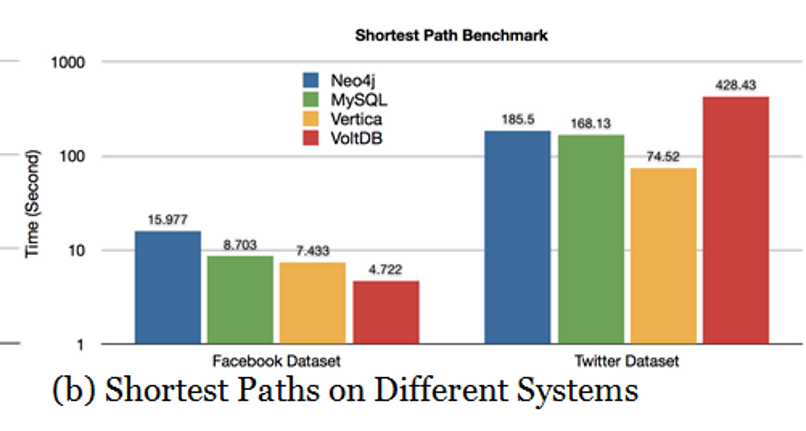
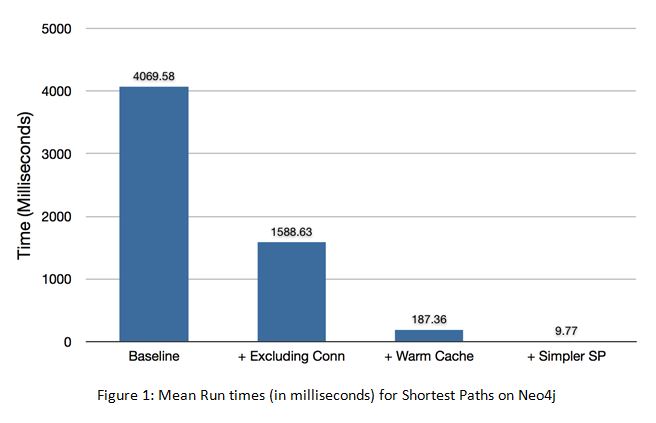
Orri Erling, in LDBC: A Socio-technical Perspective, writes in part:
I had a conversation with Michael at a DERI meeting a couple of years ago about measuring the total cost of technology adoption, thus including socio-technical aspects such as acceptance by users, learning curves of various stakeholders, whether in fact one could demonstrate an overall gain in productivity arising from semantic technologies. [in my words, paraphrased]
“Can one measure the effectiveness of different approaches to data integration?” asked I.
“Of course one can,” answered Michael, “this only involves carrying out the same task with two different technologies, two different teams and then doing a double blind test with users. However, this never happens. Nobody does this because doing the task even once in a large organization is enormously costly and nobody will even seriously consider doubling the expense.”
LDBC does in fact intend to address technical aspects of data integration, i.e., schema conversion, entity resolution, and the like. Addressing the sociotechnical aspects of this (whether one should integrate in the first place, whether the integration result adds value, whether it violates privacy or security concerns, whether users will understand the result, what the learning curves are, etc.) is simply too diverse and so totally domain dependent that a general purpose metric cannot be developed, at least not in the time and budget constraints of the project. Further, adding a large human element in the experimental setting (e.g., how skilled the developers are, how well the stakeholders can explain their needs, how often these needs change, etc.) will lead to experiments that are so expensive to carry out and whose results will have so many unquantifiable factors that these will constitute an insuperable barrier to adoption.
The need for parallel systems to judge the benefits of a new technology is a straw man. And one that is easy to dispel.
For example, if your company provides technical support, you are tracking metrics on how quickly your staff can answer questions. And probably customer satisfaction with your technical support.
Both are common metrics in use today.
Assume the suggestion that linked data to improve technical support for your products. You begin with a pilot project to measure the benefit from the suggested change.
If the length of support calls goes down or customer customer satisfaction goes up, or both, change to linked data. If not, don’t.
Naming a technology as “semantic” doesn’t change how you measure the benefits of a change in process.
LDBC will find purely machine based performance measures easier to produce than answering more difficult socio-technical issues.
But of what value are great benchmarks for a technology that no one wants to use?
See my comments under: Web Data Commons (2012) – [RDFa at 1.28% of 40.5 million websites]. Benchmarks for 1.28% of the web?