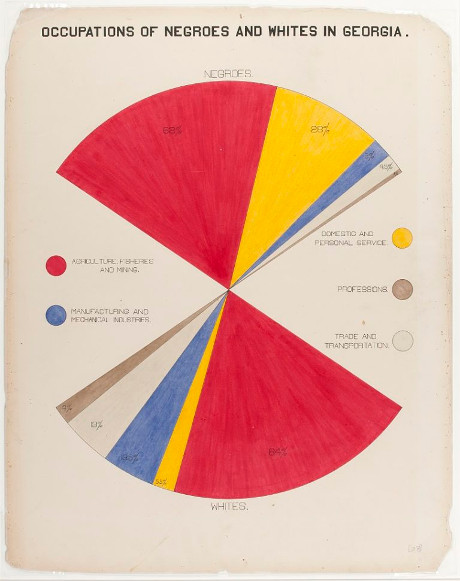
The Machines in the Valley Digital History Project by Jason Heppler.
From the post:
I am excited to finally release the digital component of my dissertation, Machines in the Valley.
My dissertation, Machines in the Valley, examines the environmental, economic, and cultural conflicts over suburbanization and industrialization in California’s Santa Clara Valley–today known as Silicon Valley–between 1945 and 1990. The high technology sector emerged as a key component of economic and urban development in the postwar era, particularly in western states seeking to diversify their economic activities. Industrialization produced thousands of new jobs, but development proved problematic when faced with competing views about land use. The natural allure that accompanied the thousands coming West gave rise to a modern environmental movement calling for strict limitations on urban growth, the preservation of open spaces, and the reduction of pollution. Silicon Valley stood at the center of these conflicts as residents and activists criticized the environmental impact of suburbs and industry in the valley. Debates over the Santa Clara Valley’s landscape tells the story not only of Silicon Valley’s development, but Americans’ changing understanding of nature and the environmental costs of urban and industrial development.
A great example of a digital project in the humanities!
How does Jason’s dissertation differ from a collection of resources on the same topic?
A collection of resources requires each of us to duplicate Jason’s work to extract the same information. Jason has curated the data, that is he has separated out the useful from the not so useful, eliminated duplicate sources that don’t contribute to the story, and provided his own analysis as a value-add to the existing data that he has organized. That means we don’t have to duplicate Jason’s work, for which we are all thankful.
How does Jason’s dissertation differ from a topic map on the same topic?
Take one of the coming soon topics for comparison:
“The Stanford Land Machine has Gone Berserk!” Stanford University and the Stanford Industrial Park (Coming Soon)
Stanford University is the largest landholder on the San Francisco Peninsula, controlling nearly 9,000 acres. In the 1950s, Stanford started acting as a real estate developer, first with the establishment of the Stanford Industrial Park in 1953 and later through several additional land development programs. These programs, however, ran into conflict with surrounding neighborhoods whose ideas for the land did not include industrialization.
Universities are never short on staff and alumni that they would prefer being staff and/or alumni from some other university. Jason will be writing about one or more such individuals under this topic. In the process of curation, he will select known details about such individuals as are appropriate for his discussion. It isn’t possible to include every known detail about any person, location, event, artifact, etc. No one would have time to read the argument being made in the dissertation.
In addition to the curation/editing process, there will be facts that Jason doesn’t uncover and/or that are unknown to anyone at present. If the governor of California can conceal an illegitimate child for ten years, it won’t be surprising to find other details about the people Jason discusses in his dissertation.
When such new information comes out, how do we put that together with the information already collected in Jason’s dissertation?
Unless you are expecting a second edition of Jason’s dissertation, the quick answer is we’re not. Not today, not tomorrow, not ever.
The current publishing paradigm is designed for republication, not incremental updating of publications. If new facts do appear and more likely enough time has passes that Jason’s dissertation is no longer “new,” some new PhD candidate will add new data, dig out the same data as Jason, and fashion a new dissertation.
If instead of imprisoning his data in prose, if Jason had his prose presentation for the dissertation and topics (as in topic maps) for the individuals, deeds, events, etc., then as more information is discovered, it could be fitted into his existing topic map of that data. Unlike the prose, a topic map doesn’t require re-publication in order to add new information.
In twenty or thirty years when Jason is advising some graduate student who wants to extend his dissertation, Jason can give them the topic map that has up to date data (or to be updated), making the next round of scholarship on this issue cumulative and not episodic.