Define and Process Data Pipelines in Hadoop with Apache Falcon
From the webpage:
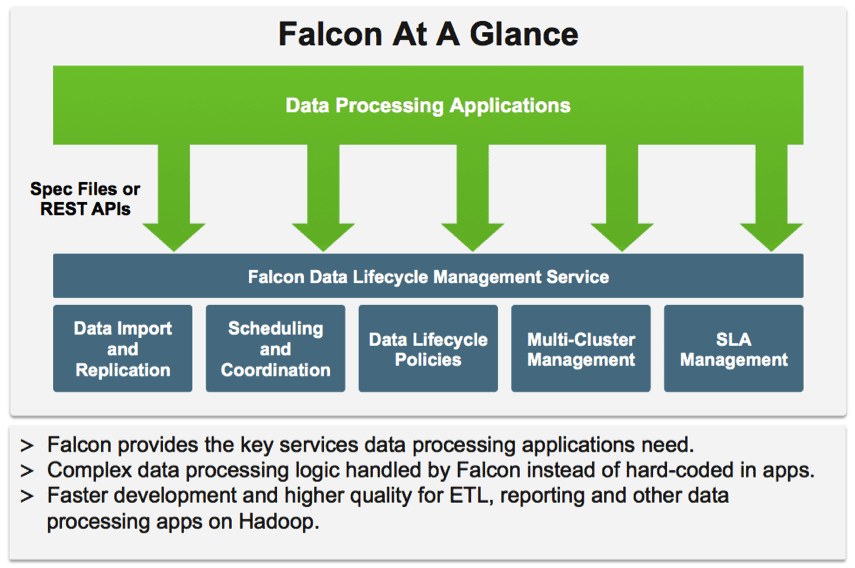
Apache Falcon simplifies the configuration of data motion with: replication; lifecycle management; lineage and traceability. This provides data governance consistency across Hadoop components.
Scenario
In this tutorial we will walk through a scenario where email data lands hourly on a cluster. In our example:
- This cluster is the primary cluster located in the Oregon data center.
- Data arrives from all the West Coast production servers. The input data feeds are often late for up to 4 hrs.
The goal is to clean the raw data to remove sensitive information like credit card numbers and make it available to our marketing data science team for customer churn analysis.
To simulate this scenario, we have a pig script grabbing the freely available Enron emails from the internet and feeding it into the pipeline.
…
Not only a great tutorial on Falcon, this tutorial is a great example of writing a tuturial!