Getting Started with Spark (in Python) by Benjamin Bengfort.
From the post:
Hadoop is the standard tool for distributed computing across really large data sets and is the reason why you see "Big Data" on advertisements as you walk through the airport. It has become an operating system for Big Data, providing a rich ecosystem of tools and techniques that allow you to use a large cluster of relatively cheap commodity hardware to do computing at supercomputer scale. Two ideas from Google in 2003 and 2004 made Hadoop possible: a framework for distributed storage (The Google File System), which is implemented as HDFS in Hadoop, and a framework for distributed computing (MapReduce).
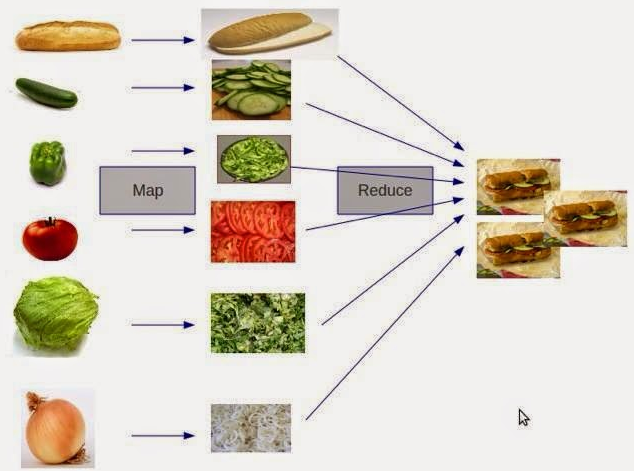
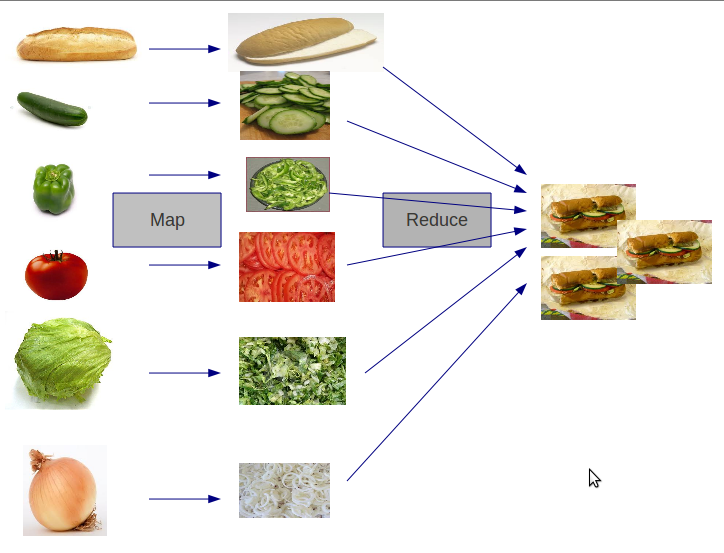
These two ideas have been the prime drivers for the advent of scaling analytics, large scale machine learning, and other big data appliances for the last ten years! However, in technology terms, ten years is an incredibly long time, and there are some well-known limitations that exist, with MapReduce in particular. Notably, programming MapReduce is difficult. You have to chain Map and Reduce tasks together in multiple steps for most analytics. This has resulted in specialized systems for performing SQL-like computations or machine learning. Worse, MapReduce requires data to be serialized to disk between each step, which means that the I/O cost of a MapReduce job is high, making interactive analysis and iterative algorithms very expensive; and the thing is, almost all optimization and machine learning is iterative.
To address these problems, Hadoop has been moving to a more general resource management framework for computation, YARN (Yet Another Resource Negotiator). YARN implements the next generation of MapReduce, but also allows applications to leverage distributed resources without having to compute with MapReduce. By generalizing the management of the cluster, research has moved toward generalizations of distributed computation, expanding the ideas first imagined in MapReduce.
Spark is the first fast, general purpose distributed computing paradigm resulting from this shift and is gaining popularity rapidly. Spark extends the MapReduce model to support more types of computations using a functional programming paradigm, and it can cover a wide range of workflows that previously were implemented as specialized systems built on top of Hadoop. Spark uses in-memory caching to improve performance and, therefore, is fast enough to allow for interactive analysis (as though you were sitting on the Python interpreter, interacting with the cluster). Caching also improves the performance of iterative algorithms, which makes it great for data theoretic tasks, especially machine learning.
In this post we will first discuss how to set up Spark to start easily performing analytics, either simply on your local machine or in a cluster on EC2. We then will explore Spark at an introductory level, moving towards an understanding of what Spark is and how it works (hopefully motivating further exploration). In the last two sections we will start to interact with Spark on the command line and then demo how to write a Spark application in Python and submit it to the cluster as a Spark job.
Be forewarned, this post uses the “F” word (functional) to describe the programming paradigm of Spark. Just so you know. 
If you aren’t already using Spark, this is about as easy a learning curve as can be expected.
Enjoy!
I first saw this in a tweet by DataMining.