A Survey of Automatic Query Expansion in Information Retrieval by Claudio Carpineto, Giovanni Romano.
Abstract:
The relative ineffectiveness of information retrieval systems is largely caused by the inaccuracy with which a query formed by a few keywords models the actual user information need. One well known method to overcome this limitation is automatic query expansion (AQE), whereby the user’s original query is augmented by new features with a similar meaning. AQE has a long history in the information retrieval community but it is only in the last years that it has reached a level of scientific and experimental maturity, especially in laboratory settings such as TREC. This survey presents a unified view of a large number of recent approaches to AQE that leverage various data sources and employ very different principles and techniques. The following questions are addressed. Why is query expansion so important to improve search effectiveness? What are the main steps involved in the design and implementation of an AQE component? What approaches to AQE are available and how do they compare? Which issues must still be resolved before AQE becomes a standard component of large operational information retrieval systems (e.g., search engines)?
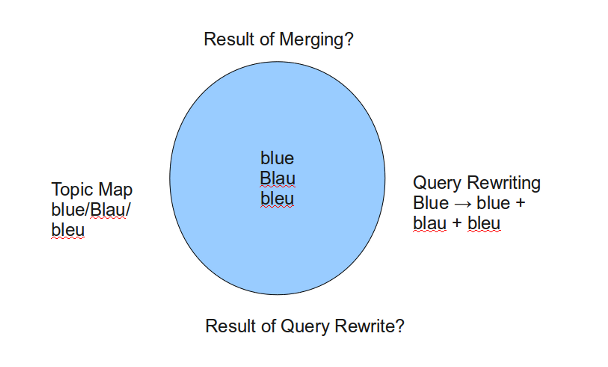
Have you heard topic maps described as being the solution to the following problem?
The most critical language issue for retrieval effectiveness is the term mismatch problem: the indexers and the users do often not use the same words. This is known as the vocabulary problem Furnas et al. [1987], compounded by synonymy (same word with different meanings, such as “java”) and polysemy (different words with the same or similar meanings, such as “tv” and “television”). Synonymy, together with word inflections (such as with plural forms, “television” versus “televisions”), may result in a failure to retrieve relevant documents, with a decrease in recall (the ability of the system to retrieve all relevant documents). Polysemy may cause retrieval of erroneous or irrelevant documents, thus implying a decrease in precision (the ability of the system to retrieve only relevant documents).
That sounds like the XWindows index merging problem doesn’t it? (Different terms being used by *nix vendors who wanted to use a common set of XWindows documentation.)
The authors describe the amount of data on the web searched with only one, two or three terms:
In this situation, the vocabulary problem has become even more serious because the paucity of query terms reduces the possibility of handling synonymy while the heterogeneity and size of data make the effects of polysemy more severe.
But the size of the data isn’t a given. What if a topic map with scoped names were used to delimit the sites searched using a particular identifier.
For example, a topic could have the name: “TRIM19” and a scope of: “http://www.ncbi.nlm.nih.gov/gene.” If you try a search with “TRIM19” at the scoping site, you get a very different result than if you use “TRIM19” with say “http://www.google.com.”
Try it, I’ll wait.
Now, imagine that your scoping topic on “TRIM19” isn’t just that one site but a topic that represents all the gene database sites known to you. I don’t know the number but it can’t be very large, at least when compared to the WWW.
That simple act of delimiting the range of your searches, makes them far less subject to polysemy.
Not to mention that a topic map could be used to supply terms for use in automated query expansion.
BTW, the survey is quite interesting and deserves a slow read with follow up on the cited references.