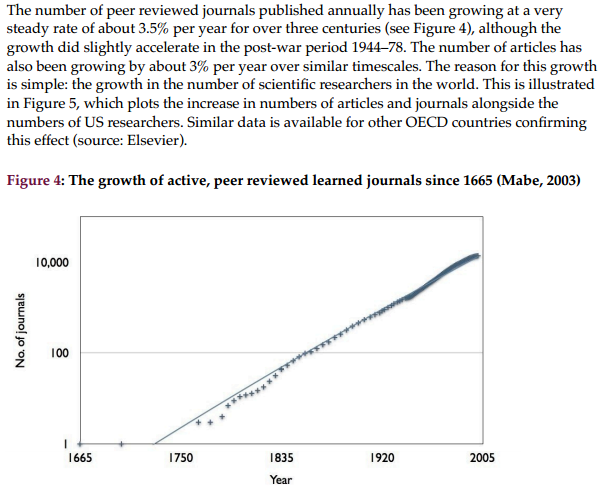
Possible Elimination of FR and CFR indexes
I don’t think I have ever posted with (Pls Read, Forward, Act) in the headline, but this merits it.
From the post:
Please see the following message from Emily Feltren, Director of Government Relations for AALL, and contact her if you have any examples to share.
Hi Advocates—
Last week, the House Oversight and Government Reform Committee reported out the Federal Register Modernization Act (HR 4195). The bill, introduced the night before the mark up, changes the requirement to print the Federal Register and Code of Federal Regulations to “publish” them, eliminates the statutory requirement that the CFR be printed and bound, and eliminates the requirement to produce an index to the Federal Register and CFR. The Administrative Committee of the Federal Register governs how the FR and CFR are published and distributed to the public, and will continue to do so.
While the entire bill is troubling, I most urgently need examples of why the Federal Register and CFR indexes are useful and how you use them. Stories in the next week would be of the most benefit, but later examples will help, too. I already have a few excellent examples from our Print Usage Resource Log – thanks to all of you who submitted entries! But the more cases I can point to, the better.
Interestingly, the Office of the Federal Register itself touted the usefulness of its index when it announced the retooled index last year: https://www.federalregister.gov/blog/2013/03/new-federal-register-index.
Thanks in advance for your help!
Emily Feltren
Director of Government Relations
American Association of Law Libraries
25 Massachusetts Avenue, NW, Suite 500
Washington, D.C. 20001
202/942-4233
efeltren@aall.org
This is seriously bad news so I decided to look up the details.
Federal Register
Title 44, Section 1504 Federal Register, currently reads in part:
Documents required or authorized to be published by section 1505 of this title shall be printed and distributed immediately by the Government Printing Office in a serial publication designated the ”Federal Register.” The Public Printer shall make available the facilities of the Government Printing Office for the prompt printing and distribution of the Federal Register in the manner and at the times required by this chapter and the regulations prescribed under it. The contents of the daily issues shall be indexed and shall comprise all documents, required or authorized to be published, filed with the Office of the Federal Register up to the time of the day immediately preceding the day of distribution fixed by regulations under this chapter. (emphasis added)
By comparison, H.R. 4195 — 113th Congress (2013-2014) reads in relevant part:
The Public Printer shall make available the facilities of the Government Printing Office for the prompt publication of the Federal Register in the manner and at the times required by this chapter and the regulations prescribed under it. (Missing index language here.) The contents of the daily issues shall constitute all documents, required or authorized to be published, filed with the Office of the Federal Register up to the time of the day immediately preceding the day of publication fixed by regulations under this chapter.
Code of Federal Regulations (CFRs)
Title 44, Section 1510 Code of Federal Regulations, currently reads in part:
(b) (b) A codification published under subsection (a) of this section shall be printed and bound in permanent form and shall be designated as the ”Code of Federal Regulations.” The Administrative Committee shall regulate the binding of the printed codifications into separate books with a view to practical usefulness and economical manufacture. Each book shall contain an explanation of its coverage and other aids to users that the Administrative Committee may require. A general index to the entire Code of Federal Regulations shall be separately printed and bound. (emphasis added)
By comparison, H.R. 4195 — 113th Congress (2013-2014) reads in relevant part:
(b) Code of Federal Regulations.–A codification prepared under subsection (a) of this section shall be published and shall be designated as the `Code of Federal Regulations’. The Administrative Committee shall regulate the manner and forms of publishing this codification. (Missing index language here.)
I would say that indexes for the Federal Register and the Code of Federal Regulations are history should this bill pass as written.
Is this a problem?
Consider the task of tracking the number of pages in the Federal Register versus the pages in the Code of Federal Regulations that may be impacted:
Federal Register – > 70,000 pages per year.
The page count for final general and permanent rules in the 50-title CFR seems less dramatic than that of the oft-cited Federal Register, which now tops 70,000 pages each year (it stood at 79,311 pages at year-end 2013, the fourth-highest level ever). The Federal Register contains lots of material besides final rules. (emphasis added) (New Data: Code of Federal Regulations Expanding, Faster Pace under Obama by Wayne Crews.)
Code of Federal Regulations – 175,496 pages (2013) plus 1,170 page index.
Now, new data from the National Archives shows that the CFR stands at 175,496 at year-end 2013, including the 1,170-page index. (emphasis added) (New Data: Code of Federal Regulations Expanding, Faster Pace under Obama by Wayne Crews.)
The bottom line is there are 175,496 pages being impacted by more than 70,000 pages per year, published in a week-day publication.
We don’t need indexes to access that material?
Congress, I don’t think “access” means what you think it means.
PS: As a research guide, you are unlikely to do better than: A Research Guide to the Federal Register and the Code of Federal Regulations by Richard J. McKinney at the Law Librarians’ Society of Washington, DC website.
I first saw this in a tweet by Aaron Kirschenfeld.