What That Election Probability Means by Nathan Yau.
From the post:
We now have our presidential candidates, and for the next few months you get to hear about the changing probability of Hillary Clinton and Donald Trump winning the election. As of this writing, the Upshot estimates a 68% probability for Clinton and 32% for Donald Trump. FiveThirtyEight estimates 52% and 48% for Clinton and Trump, respectively. Forecasts are kind of all over the place this far out from November. Plus, the numbers aren’t especially accurate post-convention.
But the probabilities will start to converge and grow more significant.
So what does it mean when Clinton has a 68% chance of becoming president? What if there were a 90% chance that Trump wins?
Some interpret a high percentage as a landslide, which often isn’t the case with these election forecasts, and it certainly doesn’t mean the candidate with a low chance will lose. If this were the case, the Cleveland Cavaliers would not have beaten the Golden State Warriors, and I would not be sitting here hating basketball.
Fiddle with the probabilities in the graphic below to see what I mean.
…
As always, visualizations from Nathan are a joy to view and valuable in practice.
You need to run it several times but here’s the result I got with “FiveThirtyEight estimates 52% and 48% for Clinton and Trump, respectively.”
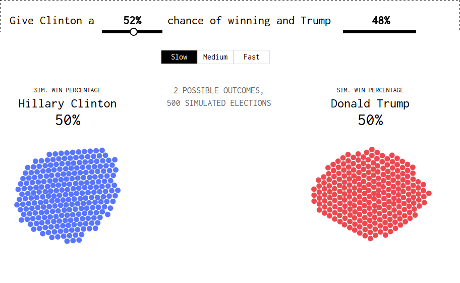
You have to wonder what a similar simulation for breach/no-breach would look like for your enterprise?
Would that be an effective marketing tool for cybersecurity?
Perhaps not if you are putting insecure code on top of insecure code but there are other solutions.
For example, having state legislatures prohibit the operation of escape from liability clauses in EULAs.
Assuming someone who has read one in sufficient detail to draft legislation. 
That could be an interesting data project. Anyone have a pointer to a collection of EULAs?
 . Moreover suppose that the expected value of
. Moreover suppose that the expected value of 