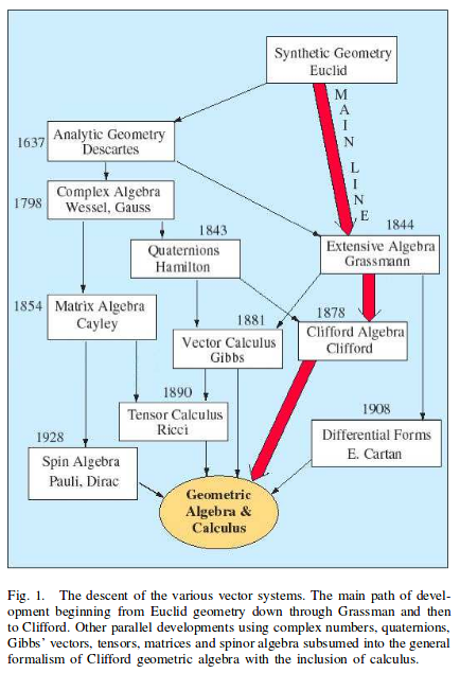
The video Provenance for Database Transformations by Val Tannen ends with a short bibliography.
Links and abstracts for the items in Val’s bibliography:
Provenance Semirings by Todd J. Green, Grigoris Karvounarakis, Val Tannen. (2007)
We show that relational algebra calculations for incomplete databases, probabilistic databases, bag semantics and whyprovenance are particular cases of the same general algorithms involving semirings. This further suggests a comprehensive provenance representation that uses semirings of polynomials. We extend these considerations to datalog and semirings of formal power series. We give algorithms for datalog provenance calculation as well as datalog evaluation for incomplete and probabilistic databases. Finally, we show that for some semirings containment of conjunctive queries is the same as for standard set semantics.
Update Exchange with Mappings and Provenance by Todd J. Green, Grigoris Karvounarakis, Zachary G. Ives, Val Tannen. (2007)
We consider systems for data sharing among heterogeneous peers related by a network of schema mappings. Each peer has a locally controlled and edited database instance, but wants to ask queries over related data from other peers as well. To achieve this, every peer’s updates propagate along the mappings to the other peers. However, this update exchange is filtered by trust conditions — expressing what data and sources a peer judges to be authoritative — which may cause a peer to reject another’s updates. In order to support such filtering, updates carry provenance information. These systems target scientific data sharing applications, and their general principles and architecture have been described in [20].
In this paper we present methods for realizing such systems. Specifically, we extend techniques from data integration, data exchange, and incremental view maintenance to propagate updates along mappings; we integrate a novel model for tracking data provenance, such that curators may filter updates based on trust conditions over this provenance; we discuss strategies for implementing our techniques in conjunction with an RDBMS; and we experimentally demonstrate the viability of our techniques in the ORCHESTRA prototype system.
Annotated XML: Queries and Provenance by J. Nathan Foster, Todd J. Green, Val Tannen. (2008)
We present a formal framework for capturing the provenance of data appearing in XQuery views of XML. Building on previous work on relations and their (positive) query languages, we decorate unordered XML with annotations from commutative semirings and show that these annotations suffice for a large positive fragment of XQuery applied to this data. In addition to tracking provenance metadata, the framework can be used to represent and process XML with repetitions, incomplete XML, and probabilistic XML, and provides a basis for enforcing access control policies in security applications.
Each of these applications builds on our semantics for XQuery, which we present in several steps: we generalize the semantics of the Nested Relational Calculus (NRC) to handle semiring-annotated complex values, we extend it with a recursive type and structural recursion operator for trees, and we define a semantics for XQuery on annotated XML by translation into this calculus.
Containment of Conjunctive Queries on Annotated Relations by Todd J. Green. (2009)
We study containment and equivalence of (unions of) conjunctive queries on relations annotated with elements of a commutative semiring. Such relations and the semantics of positive relational queries on them were introduced in a recent paper as a generalization of set semantics, bag semantics, incomplete databases, and databases annotated with various kinds of provenance information. We obtain positive decidability results and complexity characterizations for databases with lineage, why-provenance, and provenance polynomial annotations, for both conjunctive queries and unions of conjunctive queries. At least one of these results is surprising given that provenance polynomial annotations seem “more expressive” than bag semantics and under the latter, containment of unions of conjunctive queries is known to be undecidable. The decision procedures rely on interesting variations on the notion of containment mappings. We also show that for any positive semiring (a very large class) and conjunctive queries without self-joins, equivalence is the same as isomorphism.
Collaborative Data Sharing with Mappings and Provenance by Todd J. Green, dissertation. (2009)
A key challenge in science today involves integrating data from databases managed by different collaborating scientists. In this dissertation, we develop the foundations and applications of collaborative data sharing systems (CDSSs), which address this challenge. A CDSS allows collaborators to define loose confederations of heterogeneous databases, relating them through schema mappings that establish how data should flow from one site to the next. In addition to simply propagating data along the mappings, it is critical to record data provenance (annotations describing where and how data originated) and to support policies allowing scientists to specify whose data they trust, and when. Since a large data sharing confederation is certain to evolve over time, the CDSS must also efficiently handle incremental changes to data, schemas, and mappings.
We focus in this dissertation on the formal foundations of CDSSs, as well as practical issues of its implementation in a prototype CDSS called Orchestra. We propose a novel model of data provenance appropriate for CDSSs, based on a framework of semiring-annotated relations. This framework elegantly generalizes a number of other important database semantics involving annotated relations, including ranked results, prior provenance models, and probabilistic databases. We describe the design and implementation of the Orchestra prototype, which supports update propagation across schema mappings while maintaining data provenance and filtering data according to trust policies. We investigate fundamental questions of query containment and equivalence in the context of provenance information. We use the results of these investigations to develop novel approaches to efficiently propagating changes to data and mappings in a CDSS. Our approaches highlight unexpected connections between the two problems and with the problem of optimizing queries using materialized views. Finally, we show that semiring annotations also make sense for XML and nested relational data, paving the way towards a future extension of CDSS to these richer data models.
Provenance in Collaborative Data Sharing by Grigoris Karvounarakis, dissertation. (2009)
This dissertation focuses on recording, maintaining and exploiting provenance information in Collaborative Data Sharing Systems (CDSS). These are systems that support data sharing across loosely-coupled, heterogeneous collections of relational databases related by declarative schema mappings. A fundamental challenge in a CDSS is to support the capability of update exchange — which publishes a participant’s updates and then translates others’ updates to the participant’s local schema and imports them — while tolerating disagreement between them and recording the provenance of exchanged data, i.e., information about the sources and mappings involved in their propagation. This provenance information can be useful during update exchange, e.g., to evaluate provenance-based trust policies. It can also be exploited after update exchange, to answer a variety of user queries, about the quality, uncertainty or authority of the data, for applications such as trust assessment, ranking for keyword search over databases, or query answering in probabilistic databases.
To address these challenges, in this dissertation we develop a novel model of provenance graphs that is informative enough to satisfy the needs of CDSS users and captures the semantics of query answering on various forms of annotated relations. We extend techniques from data integration, data exchange, incremental view maintenance and view update to define the formal semantics of unidirectional and bidirectional update exchange. We develop algorithms to perform update exchange incrementally while maintaining provenance information. We present strategies for implementing our techniques over an RDBMS and experimentally demonstrate their viability in the ORCHESTRA prototype system. We define ProQL, iv a query language for provenance graphs that can be used by CDSS users to combine data querying with provenance testing as well as to compute annotations for their data, based on their provenance, that are useful for a variety of applications. Finally, we develop a prototype implementation ProQL over an RDBMS and indexing techniques to speed up provenance querying, evaluate experimentally the performance of provenance querying and the benefits of our indexing techniques.
Provenance for Aggregate Queries by Yael Amsterdamer, Daniel Deutch, Val Tannen. (2011)
We study in this paper provenance information for queries with aggregation. Provenance information was studied in the context of various query languages that do not allow for aggregation, and recent work has suggested to capture provenance by annotating the different database tuples with elements of a commutative semiring and propagating the annotations through query evaluation. We show that aggregate queries pose novel challenges rendering this approach inapplicable. Consequently, we propose a new approach, where we annotate with provenance information not just tuples but also the individual values within tuples, using provenance to describe the values computation. We realize this approach in a concrete construction, first for “simple” queries where the aggregation operator is the last one applied, and then for arbitrary (positive) relational algebra queries with aggregation; the latter queries are shown to be more challenging in this context. Finally, we use aggregation to encode queries with difference, and study the semantics obtained for such queries on provenance annotated databases.
Circuits for Datalog Provenance by Daniel Deutch, Tova Milo, Sudeepa Roy, Val Tannen. (2014)
The annotation of the results of database queries with provenance information has many applications. This paper studies provenance for datalog queries. We start by considering provenance representation by (positive) Boolean expressions, as pioneered in the theories of incomplete and probabilistic databases. We show that even for linear datalog programs the representation of provenance using Boolean expressions incurs a super-polynomial size blowup in data complexity. We address this with an approach that is novel in provenance studies, showing that we can construct in PTIME poly-size (data complexity) provenance representations as Boolean circuits. Then we present optimization techniques that embed the construction of circuits into seminaive datalog evaluation, and further reduce the size of the circuits. We also illustrate the usefulness of our approach in multiple application domains such as query evaluation in probabilistic databases, and in deletion propagation. Next, we study the possibility of extending the circuit approach to the more general framework of semiring annotations introduced in earlier work. We show that for a large and useful class of provenance semirings, we can construct in PTIME poly-size circuits that capture the provenance.
Incomplete but a substantial starting point exploring data provenance and its relationship/use with topic map merging.
To get a feel for “data provenance” just prior to the earliest reference here (2007), consider A Survey of Data Provenance Techniques by Yogesh L. Simmhan, Beth Plale, Dennis Gannon, published in 2005.
Data management is growing in complexity as large-scale applications take advantage of the loosely coupled resources brought together by grid middleware and by abundant storage capacity. Metadata describing the data products used in and generated by these applications is essential to disambiguate the data and enable reuse. Data provenance, one kind of metadata, pertains to the derivation history of a data product starting from its original sources.
The provenance of data products generated by complex transformations such as workflows is of considerable value to scientists. From it, one can ascertain the quality of the data based on its ancestral data and derivations, track back sources of errors, allow automated re-enactment of derivations to update a data, and provide attribution of data sources. Provenance is also essential to the business domain where it can be used to drill down to the source of data in a data warehouse, track the creation of intellectual property, and provide an audit trail for regulatory purposes.
In this paper we create a taxonomy of data provenance techniques, and apply the classification to current research efforts in the field. The main aspect of our taxonomy categorizes provenance systems based on why they record provenance, what they describe, how they represent and store provenance, and ways to disseminate it. Our synthesis can help those building scientific and business metadata-management systems to understand existing provenance system designs. The survey culminates with an identification of open research problems in the field.
Another rich source of reading material!