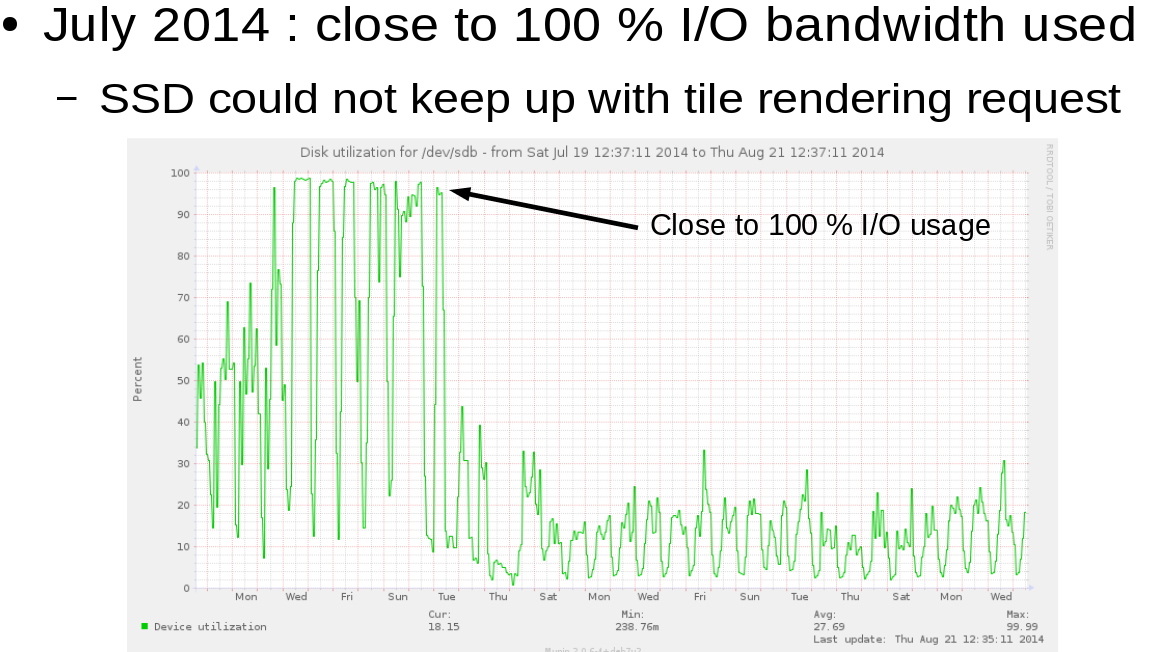
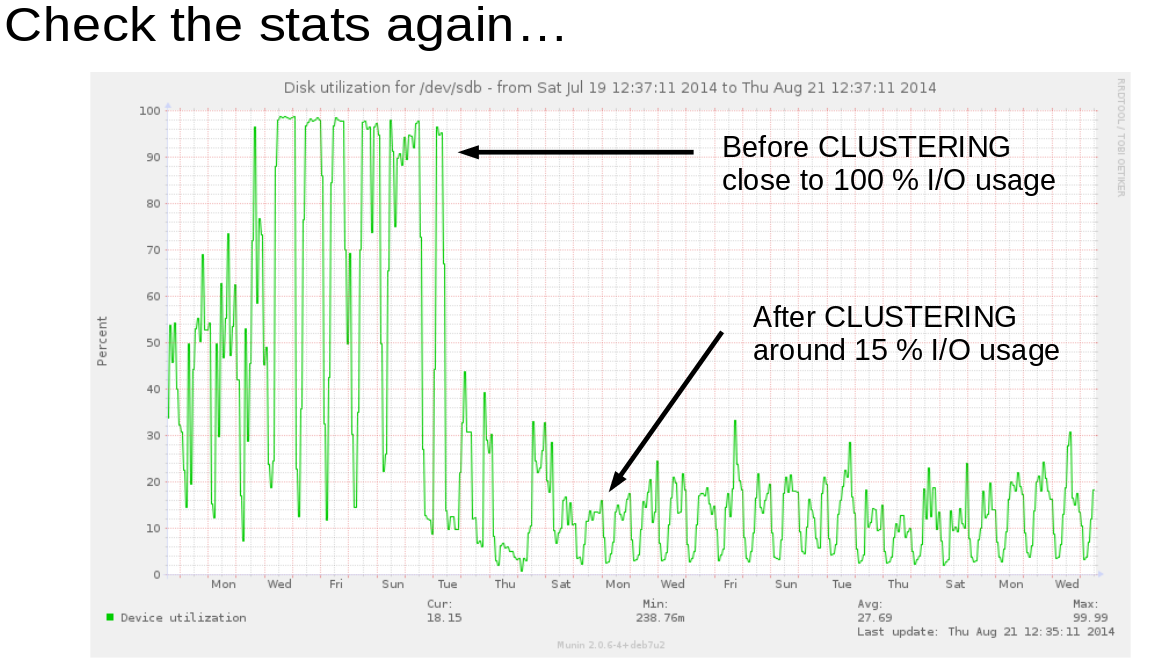
Interactive 3D Clusters of all 721 Pokémon Using Spark and Plotly by Max Woolf.
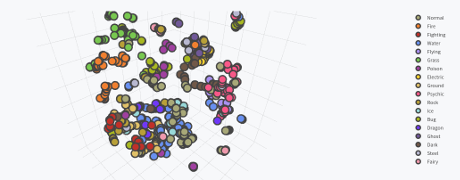
My screen capture falls far short of doing justice to the 3D image, not to mention it isn’t interactive. See Max’s post if you really want to appreciate it.
From the post:
There has been a lot of talk lately about Pokémon due to the runaway success of Pokémon GO (I myself am Trainer Level 18 and on Team Valor). Players revel in the nostalgia of 1996 by now having the ability catching the original 151 Pokémon in real life.
However, while players most-fondly remember the first generation, Pokémon is currently on its sixth generation, with the seventh generation beginning later this year with Pokémon Sun and Moon. As of now, there are 721 total Pokémon in the Pokédex, from Bulbasaur to Volcanion, not counting alternate Forms of several Pokémon such as Mega Evolutions.
In the meantime, I’ve seen a few interesting data visualizations which capitalize on the frenzy. A highly-upvoted post on the Reddit subreddit /r/dataisbeautiful by /u/nvvknvvk charts the Height vs. Weight of the original 151 Pokémon. Anh Le of Duke University posted a cluster analysis of the original 151 Pokémon using principal component analysis (PCA), by compressing the 6 primary Pokémon stats into 2 dimensions.
However, those visualizations think too small, and only on a small subset of Pokémon. Why not capture every single aspect of every Pokémon and violently crush that data into three dimensions?
…

If you need encouragement to explore the recent release of Spark 2.0, Max’s post that in abundance!
Caveat: Pokémon is popular outside of geek/IT circles. Familiarity with Pokémon may result in social interaction with others and/or interest in Pokémon. You have been warned.