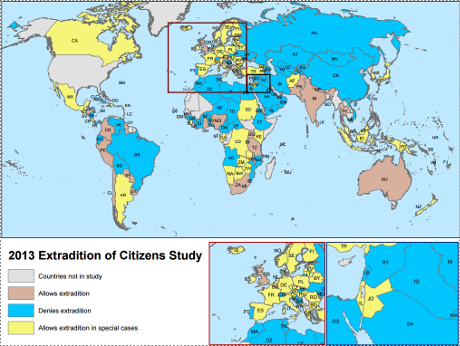
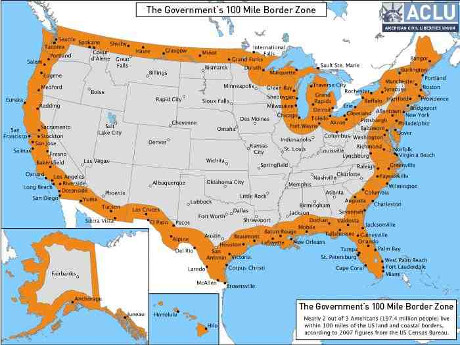
Teaching Cybersecurity Law and Policy: My Revised 62-Page Syllabus/Primer by Robert Chesney.
From the post:
Cybersecurity law and policy is a fun subject to teach. There is vast room for creativity in selecting topics, readings and learning objectives. But that same quality makes it difficult to decide what to cover, what learning objectives to set, and which reading assignments to use.
With support from the Hewlett Foundation, I’ve spent a lot of time in recent years wrestling with this challenge, and last spring I posted the initial fruits of that effort in the form of a massive “syllabus” document. Now, I’m back with version 2.0.
At 62 pages (including a great deal of original substantive content, links to readings, and endless discussion prompts), it is probably most accurate to describe it as a hybrid between a syllabus and a textbook. Though definitely intended in the first instance to benefit colleagues who teach in this area or might want to do so, I think it also will be handy as a primer for anyone—practitioner, lawyer, engineer, student, etc.—who wants to think deeply about the various substrands of this emergent field and how they relate to one another.
Feel free to make use of this any way you wish. Share it with others who might enjoy it (or at least benefit from it), and definitely send me feedback if you are so inclined (rchesney@law.utexas.edu or @bobbychesney on Twitter).
The technical side of the law is deeply fascinating and perhaps even more so in cybersecurity. It’s worth noting that Chesney does a great job laying out normative law as a given.
You are not going to find an analysis of the statutes cited to identify who benefits or is penalized by those statutes. You know the adage about laws that prohibit the rich and the poor equally from sleeping under bridges? The same applies to cybersecurity statutes. They are always presented as fair and accomplished public policies. Nothing could be further from the truth.
That’s not a criticism of Chesney’s syllabus, the technical side of existing laws is a quite lucrative one for anyone who masters its complexities. And it is certainly a worthy subject for study. I mention looking behind laws as it were to promote an awareness that shaping the winners and losers encoded in laws, also merits your attention.
Cybersecurity laws have adversely impacted security researchers, as steps suggested to reduce the odds of your liability for disclosure of a vulnerability show:
…
- Don’t ask for money in exchange for keeping vulnerability information quiet. Researchers have been accused of extortion after saying they would reveal the vulnerability unless the company wants to pay a finder’s fee or enter into a contract to fix the problem. See, e.g. GameSpy warns security researcher
- If you are under a non-disclosure agreement, you may not be allowed to publish. Courts are likely to hold researchers to their promises to maintain confidentiality.
- You may publish information to the general public, but do not publish directly to people you know intend to break the law.
- Consider disclosing to the vendor or system administrator first and waiting a reasonable and fair amount of time for a patch before publishing to a wider audience.
- Consider having a lawyer negotiate an agreement with the company under which you will provide details about the vulnerability—thus helping to make the product better—in exchange for the company’s agreement not to sue you for the way you discovered the problem.
- Consider the risks and benefits of describing the flaw with proof-of-concept code, and whether that code could describe the problem without unnecessarily empowering an attacker.
- Consider whether your proof of concept code is written or distributed in a manner that suggests it is “primarily” for the purpose of gaining unauthorized access or unlawful data interception, or marketed for that purpose. Courts look both to the attributes of the tool itself as well as the circumstances surrounding the distribution of that tool to determine whether it would violate such a ban.
- Consider whether to seek advance permission to publish, even if getting it is unlikely.
- Consider how to publish your advisory in a forum and manner that advances the state of knowledge in the field.
- Do not publish in a manner that enables or a forum that encourages copyright infringement, privacy invasions, computer trespass or other offenses.
…
The oppression of independent security researchers in cybersecurity law is fairly heavy-handed but there are subtleties and nuances that lie deeper in the interests that drove drafting of such legislation.
Fairly obvious but have you noticed there is no liability for faulty software? The existence of EULAs, waivers of liability, are a momentary diversion. It is a rare case when a court finds such agreements enforceable, outside the context of software.
The discovery and publication of vulnerabilities, should vendors not fix them in a timely fashion, would raise serious questions about their “gross negligence” in failing to fix such vulnerabilities. And thence to greater abilities to attack EULAs.
Not only are major software vendors bastards, but they are clever bastards as well.
That’s only one example of an unlimited number once you ask qui bono? (whose good) for any law.
In a world where governments treat the wholesale slaughter of millions of people of color and condemning of millions to lives of deprivation and want as “business as usual,” you may ask, what obligation is there to obey any cybersecurity or other law?
Your obligation to obey any law is a risk assesment of the likelihood of a soverign attributing a particular act to you. The better your personal security, the greater the range of behavior choices you have.