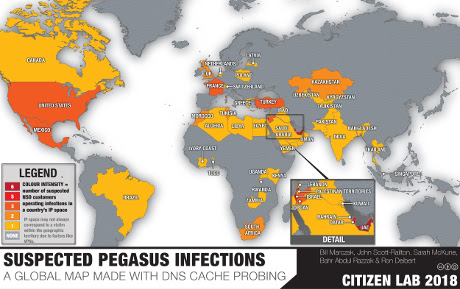
MINIX — The most popular OS in the world, thanks to Intel by Bryan Lunduke
Unless most claims of being “widespread,” the claims about MINIX, a secret OS on Intel chips, appear to be true.
From the post:
…
MINIX is running on “Ring -3” (that’s “negative 3”) on its own CPU. A CPU that you, the user/owner of the machine, have no access to. The lowest “Ring” you have any real access to is “Ring 0,” which is where the kernel of your OS (the one that you actually chose to use, such as Linux) resides. Most user applications take place in “Ring 3” (without the negative).
…
The second thing to make my head explode: You have zero access to “Ring -3” / MINIX. But MINIX has total and complete access to the entirety of your computer. All of it. It knows all and sees all, which presents a huge security risk — especially if MINIX, on that super-secret Ring -3 CPU, is running many services and isn’t updated regularly with security patches.
…
For details, see Replace your exploit-ridden firmware with a Linux kernel, by Ron Minnich, et. al. (Seventy-one (71) slides. File name: Replace UEFI with Linux.pdf. I grabbed a copy just in case this one goes away.)
Intel material on UEFI.
Unified Extensible Firmware Interface Forum, consortium website. For the latest versions of specifications see: http://www.uefi.org/specifications but as of today, see:
ACPI Specification Version 6.2 (Errata A)
ACPI can first be understood as an architecture-independent power management and configuration framework that forms a subsystem within the host OS. This framework establishes a hardware register set to define power states (sleep, hibernate, wake, etc). The hardware register set can accommodate operations on dedicated hardware and general purpose hardware. [page 1.] 1177
UEFI Specification Version 2.7 (Errata A)
T
his Unified Extensible Firmware Interface (hereafter known as UEFI) Specification describes an interface between the operating system (OS) and the platform firmware. UEFI was preceded by the Extensible Firmware Interface Specification 1.10 (EFI). As a result, some code and certain protocol names retain the EFI designation. Unless otherwise noted, EFI designations in this specification may be assumed to be part of UEFI.
The interface is in the form of data tables that contain platform-related information, and boot and runtime service calls that are available to the OS loader and the OS. Together, these provide a standard environment for booting an OS. This specification is designed as a pure interface specification. As such, the specification defines the set of interfaces and structures that platform firmware must implement. Similarly, the specification defines the set of interfaces and structures that the OS may use in booting. How either the firmware developer chooses to implement the required elements or the OS developer chooses to make use of those interfaces and structures is an implementation decision left for the developer.
…
Using this formal definition, a shrink-wrap OS intended to run on platforms compatible with supported processor specifications will be able to boot on a variety of system designs without further platform or OS customization. The definition will also allow for platform innovation to introduce new features and functionality that enhance platform capability without requiring new code to be written in the OS boot sequence. [page 1.] 2575
UEFI Shell Specification Version 2.2
The UEFI Shell environment provides an API, a command prompt and a rich set of commands that extend and enhance the UEFI Shell’s capability. [page 1] 258
UEFI Platform Initialization Specification Version 1.6
This specification defines the core code and services that are required for an implementation of the Pre-EFI Initialization (PEI) phase of the Platform Initialization (PI) specifications (hereafter referred to as the “PI Architecture”). This PEI core interface specification (CIS) does the following:
[vol. 1, page 1] 1627
UEFI Platform Initialization Distribution Packaging Specification Version 1.1
This specification defines the overall architecture and external interfaces that are required for distribution of UEFI/PI source and binary files. [page 1] 359
TCG EFI Platform Specification
PC Client Work Group EFI Platform Specification, Version 1.22, Revision 15
This document is about the processes that boot an Extensible Firmware Interface (EFI) platform and load an OS on that platform. Specifically, this specification contains the requirements for measuring EFI unique events into TPM PCRs and adding boot event entries into the Event Log. [page 5] 43
TCG EFI Protocol Specification
PC Client Work Group EFI Protocol Specification, Family “2.0”, Level 00, Revision 00.13
The purpose of this document is to define a standard interface to the TPM on an EFI platform. This standard interface is useful on any instantiations of an EFI platform that conforms to the EFI Specification. This EFI Protocol Specification is a pure interface specification that provides no information on “how” to construct the underlying firmware implementation. [page 9] 46
By my count, 5,585 pages from the Unified Extensible Firmware Interface Forum, consortium website alone.
Of course, then you need to integrate it with other documentation, your test results and the results of others, not to mention blogs and other sources.
Breaking this content into useful subjects would be non-trivia, but how much are universal vulnerabilities worth?