Audiogram from New York Public Radio.
My interest in Audiogram was sparked by the need to convert an audio file into video, so the captioning service at YouTube would provide a rough cut at transcribing the audio.
From the post:
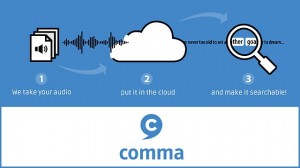
Audiogram is a library for generating shareable videos from audio clips.
Here are some examples of the audiograms it creates:
- https://twitter.com/WNYC/status/707576942837374976
- https://www.facebook.com/NoteToSelfPodcast/videos/
597741940383645/- https://twitter.com/WNYC/status/751089421026402304
- https://www.facebook.com/BrianLehrerWNYC/videos/
1045228085513942/Why does this exist?
Unlike audio, video is a first-class citizen of social media. It’s easy to embed, share, autoplay, or play in a feed, and the major services are likely to improve their video experiences further over time.
Our solution to this problem at WNYC was this library. Given a piece of audio we want to share on social media, we can generate a video with that audio and some basic accompanying visuals: a waveform of the audio, a theme for the show it comes from, and a caption.
For more on the backstory behind audiograms, read this post.
…
I hope to finish the transcript I obtained from YouTube later this week and will be posted it, along with all the steps I took to produce it.
Hiding either the process and/or result would be poor repayment to all those who have shared so much, like New York Public Radio.