Introducing Espresso – LinkedIn’s hot new distributed document store by Aditya Auradkar.
From the post:
Espresso is LinkedIn’s online, distributed, fault-tolerant NoSQL database that currently powers approximately 30 LinkedIn applications including Member Profile, InMail (LinkedIn’s member-to-member messaging system), portions of the Homepage and mobile applications, etc. Espresso has a large production footprint at LinkedIn with over a dozen clusters in use. It hosts some of the most heavily accessed and valuable datasets at LinkedIn serving millions of records per second at peak. It is the source of truth for hundreds of terabytes (not counting replicas) of data.
Motivation
To meet the needs of online applications, LinkedIn traditionally used Relational Database Management Systems (RDBMSs) such as Oracle and key-value stores such as Voldemort – both serving different use cases. Much of LinkedIn requires a primary, strongly consistent, read/write data store that generates a timeline-consistent change capture stream to fulfill nearline and offline processing requirements. It has become apparent that many, if not most, of the primary data requirements of LinkedIn do not require the full functionality of monolithic RDBMSs, nor can they justify the associated costs.
…
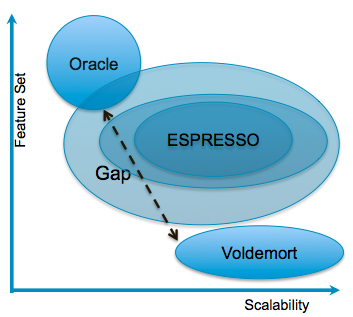
A must read if you are concerned with BigData and/or distributed systems.
A refreshing focus on requirements, as opposed to engineering by slogan, “all the world’s a graph.”
Looking forward to more details on Expresso as they emerge.
I first saw this in a tweet by Martin Kleppmann.