Apache Spark on HDP: Learn, Try and Do by Jules S. Damji.
I wanted to leave you with something fun to enjoy this evening. I am off to read a forty-eight (48) page bill that would make your ninth (9th) grade English teacher hurl. It’s really grim stuff that boils down to a lot of nothing but you have to parse through it to make that evident. More on that tomorrow.
From the post:
Not a day passes without someone tweeting or re-tweeting a blog on the virtues of Apache Spark.
At a Memorial Day BBQ, an old friend proclaimed: “Spark is the new rub, just as Java was two decades ago. It’s a developers’ delight.”
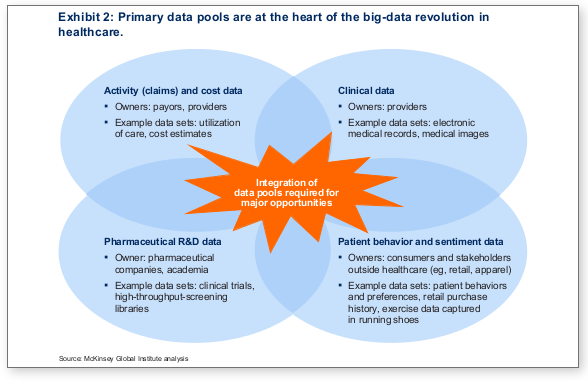
Spark as a distributed data processing and computing platform offers much of what developers’ desire and delight—and much more. To the ETL application developer Spark offers expressive APIs for transforming data; to the data scientists it offers machine libraries, MLlib component; and to data analysts it offers SQL capabilities for inquiry.
In this blog, I summarize how you can get started, enjoy Spark’s delight, and commence on a quick journey to Learn, Try, and Do Spark on HDP, with a set of tutorials.
…
I don’t know which is more disturbing. That Spark was being discussed at a Memorial Day BBQ or that anyone was sober enough to remember it. Life seems to change when you are older than the average cardiologist.
Sorry! Where were we, oh, yes, Saptak Sen has collected a set of tutorials to introduce you to Spark on the HDP Sandbox.
Near the bottom of the page, Apache Zeppelin (incubating) is mentioned along with Spark. Could use it to enable exploration of a data set. Could also use it so that users “discover” on their own that your analysis of the data is indeed correct. 
Due diligence means not only seeing the data as processed but the data from where that data was drawn, what pre-processing was done on that data, the circumstances under which the “original” data came into being, the algorithms applied at all stages, to name only a few considerations.
The demonstration of a result merits, “that’s interesting” until you have had time to verify it. “Trust” comes after verification.

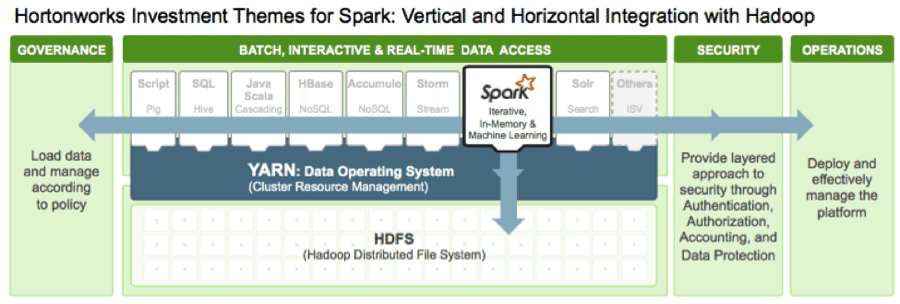
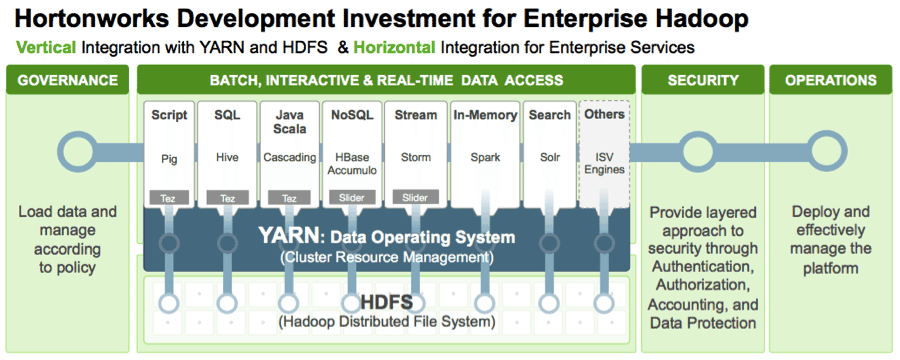
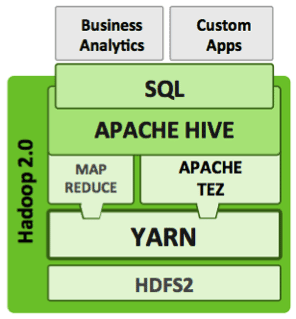 Tez is a low-level runtime engine not aimed directly at data analysts or data scientists. Frameworks need to be built on top of Tez to expose it to a broad audience… enter SQL and interactive query in Hadoop.
Tez is a low-level runtime engine not aimed directly at data analysts or data scientists. Frameworks need to be built on top of Tez to expose it to a broad audience… enter SQL and interactive query in Hadoop.