A continuation of my post Avoiding Viruses in DNC/DCCC/CF Excel Files.
Where Avoiding Viruses… focused on avoiding the hazards and dangers of Excel-born viruses, this post focuses on preparing the DNC/DCCC/CF Excel files from Guccifer 2.0, as of October 7, 2016, for further analysis.
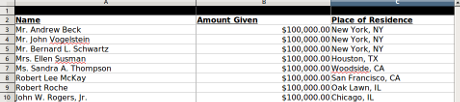
As I mentioned before, you could search through all 517 files to date, separately, using Excel. That thought doesn’t bring me any joy. You?
Instead, I’m proposing that we prepare the files to be concatenated together, resulting in one fairly large file, which we can then search and manipulate as one entity.
As a data cleanliness task, I prefer to prefix every line in every csv export, with the name of its original file. That will enable us to extract lines that mention the same person over several files and still have a bread crumb trail back to the original files.
Munging all the files together without such a step, would leave us either grepping across the collection and/or using some other search mechanism. Why not plan on avoiding that hassle?
Given the number of files requiring prefixing, I suggest the following:
for f in *.csv*; do
sed -i "s/^/$f,/" $f
done
This shell script uses sed with the -i switch, which means sed changes files in place (think overwriting specified part). Here the s/ means to substitute at the ^, start of each line, $f, the filename plus a comma separator and the final $f, is the list of files to be processed.
There are any number of ways to accomplish this task. Your community may use a different approach.
The result of my efforts is: guccifer2.0-all-spreadsheets-07October2016.gz, which weighs in at 61 MB compressed and 231 MB uncompressed.
I did check and despite having variable row lengths, it does load in my oldish version of gnumeric. All 1030828 lines.
That’s not all surprising for gnumeric, considering I’m running 24 GB of physical RAM. Your performance may vary. (It did hesitate loading it.)
There is much left to be done, such as deciding what padding is needed to even out all the rows. (I have ideas, suggestions?)
Tools to manipulate the CSV. I have a couple of stand-bys and a new one that I located while writing this post.
And, of course, once the CSV is cleaned up, what other means can we use to explore the data?
My focus will be on free and high performance (amazing how often those are found together Larry Ellison) tools that can be easily used for exploring vast seas of spreadsheet data.
Next post on these Excel files, Monday, October 10, 2016.
I am downloading the cf.7z Guccifer 2.0 drop as I write this update.
Watch for updates on the comprehensive file list and Excel files next Monday. October 8, 2016, 01:04 UTC.