I point this out only partially in jest.
Legend has it that the Deity knows the future consequences of present actions.
Google, on the other hand, has the hubris to decide matters that will impact all of us without understanding any future consequences and/or consultation with those to be affected.
Take for example Google’s Loon project.
In brief the Loon project will release a series of balloons that float in the stratosphere to offer global cellphone service, which will enable anyone in the world to connect to the Internet.
Ground-based astronomy is difficult enough with increasing light pollution.
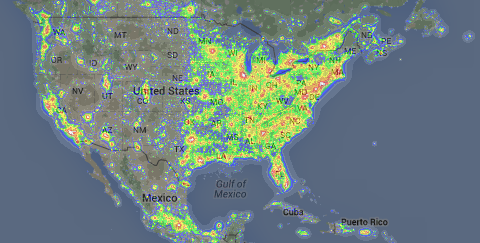
That map is only a portion of the world map at Dark Site Finder
In addition to growing light pollution, astronomers will have to content with random sky junk from Google’s Loon project. Balloons move at the whim of the wind, making it impossible for astronomers to dodge around Google sky junk for their observations.
Don’t imagine that the surveillance potential will be lost on nation states, which will quickly use Google balloons as cover for their own. How are you going to distinguish one balloon from another at the edge of space?
Moreover, despite protests to the contrary, Google’s motivation is fairly clear, the more people with access to the Internet, the more victims of Internet advertising for Google to deliver to its clients.
That the current Internet has adopted an ad-based model is no reason to presume that alternative models on a country by country basis could not be different. Bell telephone survived, nay thrived, for decades without a single ad being delivered by your phone service. Think about that, not a single ad and more reliable service over a wider area than any cellphone provider can boast of today.
Hidden deeper in Google’s agenda is the White West Paternalism that has decided, like being Christian was once upon a time, having access to the Internet is a necessity for everyone. The third world is still paying for missionary intervention in the 17th century and later, must we really repeat that sad episode?
The goal isn’t to benefit people who don’t have access to the Internet but to remake them into more closely fitting our “ideal” of a technology-based society.
The common and infantile belief that technology will bring democracy and other assorted benefits was thoroughly rebutted in 
Why Technology Hasn’t Delivered More Democracy by Thomas Carothers. Democracy and other social benefits are far more complicated, people complicated, than any simple technological “fix” can address.
I think the word I am search for is “hubris.”
Unfortunately, unlike an individual case of “hubris,” when spreading the Internet fails to produce the desired outcomes, it won’t impact only Google, but the rest of humanity as well.
I first saw the Google image in a tweet by Marko A. Rodriguez.