Immediate reactions to How To Brick A School Bus, Data Science Helps Park It (Part 1) include:
- Blocking a public street with a bricked school bus is a crime.
- Publicly committing a crime isn’t on your bucket list.
- School buses are expensive.
- Turning over a school bus is dangerous.
All true and all likely to diminish any enthusiasm for participation.
Bright yellow school buses bricked and blocking transportation routes attract the press like flies to …, well, you know, but may not be your best option.
Alternatives to a Bricked School Bus
Despite the government denying your right to assemble near the inauguration on January 20, 2017 in Washington, D.C., what other rights could lead to a newsworthy result?
You have the right to travel, although the Supreme Court has differed on the constitutional basis for that right. (Constitution of the United States of America: Analysis and Interpretation, 14th Admendment, page 1834, footnote 21).
You also have the right to be inattentive, which I suspect is secured 9th Amendment:
The enumeration in the Constitution, of certain rights, shall not be construed to deny or disparage others retained by the people.
If we put the right to travel together with the right to be inattentive (or negligent), then it stands to reason that your car could run out of gas on the highways normally used to attend an inauguration.
Moreover, we know from past cases, that drivers have not been held to be negligent simply for running out of gas, even at the White House.
Where to Run Out of Gas?
Interesting question and the one that originally had me reaching for historic traffic data.
It does exist, yearly summaries (Virginia), Inrix (Washington, DC), Traffic Volume Maps (District Department of Transportation), and others.
But we don’t want to be like the data scientist who used GPS and satellite data to investigate why you can’t get a taxi in Singapore when it rains. Starting Data Analysis with Assumptions Crunching large amounts of data discovered that taxis in Singapore stop moving when it rains.
Interesting observation but not the answer to the original question. Asking a local taxi driver, it was discovered that draconian traffic liability laws are the reason taxi drivers pull over when it rains. Not a “big data” question at all.
What Do We Know About DC Metro Traffic Congestion?
Let’s review what is commonly known about DC metro traffic congestion:
D.C. tops list of nation’s worst traffic gridlock (2015), Study ranks D.C. traffic 2nd-worst in U.S. (2016), DC Commuters Abandon Metro, Making Already Horrible Traffic Even Worse (metro repairs make traffic far worse).
At the outset, we know that motor vehicle traffic is a chaotic system, so small changes, such as addition impediment of traffic flow by cars running out of gas, can have large effects. Especially on a system that teeters on the edge of gridlock every day.
The loss of Metro usage has a cascading impact on metro traffic (from above). Which means blockage of access to Metro stations will exacerbate the impact of blockages on the highway system.
Time and expense could be spent on overly precise positioning of out-of-gas cars, but a two part directive is just as effective if not more so:
- Go to Metro stations ingresses.
- Go to any location on traffic map that is not red.
Here’s a sample traffic map that has traffic cameras:
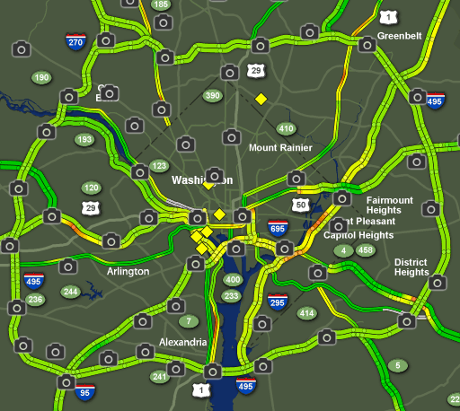
From Fox5 DC but it is just one of many.
The use of existing traffic maps removes the need to construct the same and enable chaotic participation, which means you quite innocently ran out of gas and did not at any time contact and/or conspire with others to run out of gas.
Conspiracy is a crime and you should always avoid committing crimes.
General Comments
You may be wondering if authorities being aware of a theoretical discussion of people running out of gas will provoke effective counter measures?
I don’t think so and here’s why: What would be the logical response of an authority? Position more tow trucks? Setup temporary refueling stations?
Do you think the press will be interested in those changes? Such that not only do you have the additional friction of the additional equipment but the press buzzing about asking about the changes?
An authorities best strategy would be to do nothing at all but that advice is rarely taken. At the very best, local authorities will make transportation even more fragile in anticipation someone might run out of gas.
The numbers I hear tossed about as additional visitors, some activities are expecting more than 100,000 (Women’s March on Washington), so even random participation in running out of gas should have a significant impact.
What if they held the inauguration to empty bleachers?
Data Science Traditionalists – Don’t Re-invent the Wheel
Nudging a chaotic traffic system into gridlock, for hours if not more than a day, may not strike you as traditional data science.
Perhaps not but please don’t re-invent the wheel.
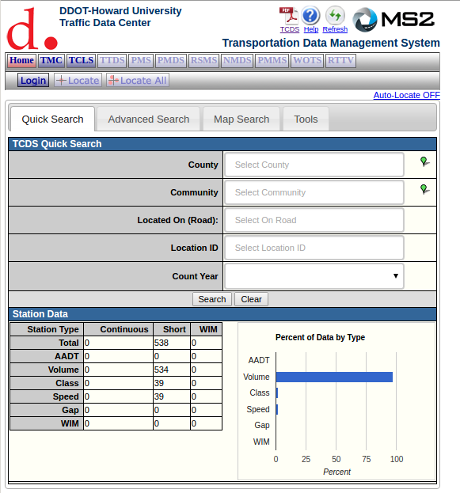
If you want to be more precise, perhaps to block particular activities or locations, let me direct you to the Howard University Transportation Safety Data Center.
They have the Traffic Count Database System (TCDS). Two screen shots that don’t do it justice:
From their guide to the system:
The Traffic Count Database System (TCDS) module is a powerful tool for the traffic engineer or planner to organize an agency’s traffic count data. It allows you to upload data from a traffic counter; view graphs, lists and reports of historic traffic count data; search for count data using either the database or the Google map; and print or export data to your desktop.
This guide is for users who are new to the TCDS system. It will provide you with the tools to carry out many common tasks. Any features not discussed in this guide are considered advanced features. If you have further questions, feel free to explore the online help guide or to contact the staff at MS2 for assistance.
I have referred to the inauguration of president-elect Donald J. Trump but the same lessons are applicable, with local modifications, to many other locations.
PS: Nothing should be construed as approval and/or encouragement that you break local laws in any venue. Those vary from jurisdiction to jurisdiction and what are acceptable risks and consequences are entirely your decision.
If you do run out of gas in or near Washington, DC on January 20, 2017, be polite to first-responders, including police officers. If you don’t realize your real enemies lie elsewhere, then you too have false class consciousness.
If you are tail-gating on the “Beltway,” offer responders a soft drink (they are on duty) and a hot dog.

 Ermilov speeds through a number of resources, documents, JS libraries, not to mention his source code for the project. You are likely to hit pause during this video.
Ermilov speeds through a number of resources, documents, JS libraries, not to mention his source code for the project. You are likely to hit pause during this video.