Facebook, despite its spying, censorship, and being a shill for the U.S. government, isn’t entirely without value.
For example, this post by Simon St. Laurent:

Drew this response from Peter Cooper:
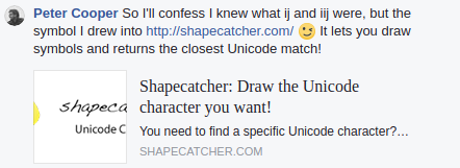
Which if you follow the link: Shapecatcher: Unicode Character Recognition you find:
Draw something in the box!
And let shapecatcher help you to find the most similar unicode characters!
Currently, there are 11817 unicode character glyphs in the database. Japanese, Korean and Chinese characters are currently not supported.
(emphasis in original)
I take “Japanese, Korean and Chinese characters are currently not supported.” means Anatolian Hieroglyphs; Cuneiform, Cuneiform Numbers and Punctuation, Early Dynastic Cuneiform, Old Persian, Ugaritic; Egyptian Hieroglyphs; Meroitic Cursive, and Meroitic Hieroglphs are not supported as well.
But my first thought wasn’t discovery of glyphs in Unicode Code Charts, although useful, but shape searching dictionaries, such as Faulkner’s A Concise Dictionary of Middle Egyptian.
A sample from Faulkner’s (1991 edition):

Or, The Student’s English-Sanskrit Dictionary by Vaman Shivram Apte (1893):

Imagine being able to search by shape for either dictionary! Not just as a gylph but as a set of glyphs, within any entry!
I suspect that’s doable based on Benjamin Milde‘s explanation of Shapecatcher:
…
Under the hood, Shapecatcher uses so called “shape contexts” to find similarities between two shapes. Shape contexts, a robust mathematical way of describing the concept of similarity between shapes, is a feature descriptor first proposed by Serge Belongie and Jitendra Malik.
You can find an indepth explanation of the shape context matching framework that I used in my Bachelor thesis (“On the Security of reCATPCHA”). In the end, it is quite a bit different from the matching framework that Belongie and Malik proposed in 2000, but still based on the idea of shape contexts.
The engine that runs this site is a rewrite of what I developed during my bachelor thesis. To make things faster, I used CUDA to accelereate some portions of the framework. This is a fairly new technology that enables me to use my NVIDIA graphics card for general purpose computing. Newer cards are quite powerful devices!
…
That was written in 2011 and no doubt shape matching has progressed since then.
No technique will be 100% but even less than 100% accuracy will unlock generations of scholarly dictionaries, in ways not imagined by their creators.
If you are interested, I’m sure Benjamin Milde would love to hear from you.