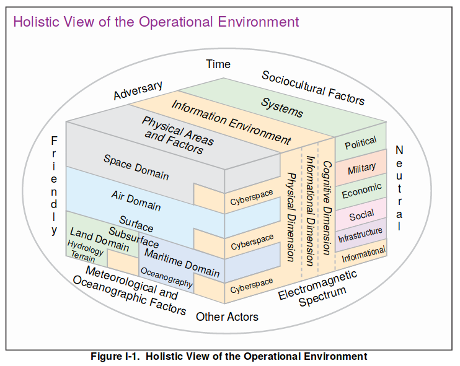
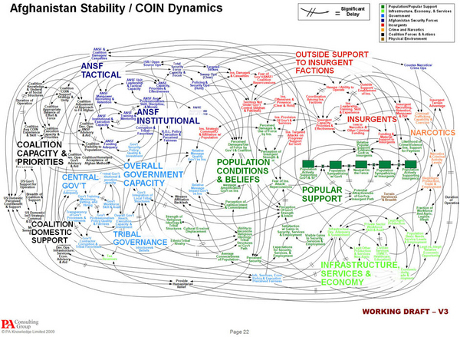
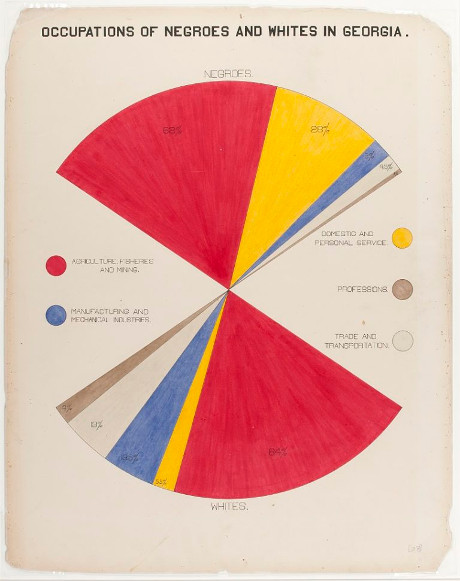
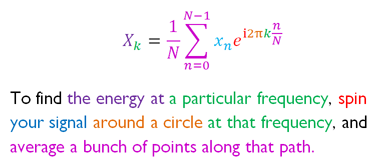No, not a post about R versus Python but about R and Tolstoy‘s War and Peace.
Using R to Gain Insights into the Emotional Journeys in War and Peace by Wee Hyong Tok.
From the post:
How do you read a novel in record time, and gain insights into the emotional journey of main characters, as they go through various trials and tribulations, as an exciting story unfolds from chapter to chapter?
I remembered my experiences when I start reading a novel, and I get intrigued by the story, and simply cannot wait to get to the last chapter. I also recall many conversations with friends on some of the interesting novels that I have read awhile back, and somehow have only vague recollection of what happened in a specific chapter. In this post, I’ll work through how we can use R to analyze the English translation of War and Peace.
War and Peace is a novel by Leo Tolstoy, and captures the salient points about Russian history from the period 1805 to 1812. The novel consists of the stories of five families, and captures the trials and tribulations of various characters (e.g. Natasha and Andre). The novel consists of about 1400 pages, and is one of the longest novels that have been written.
We hypothesize that if we can build a dashboard (shown below), this will allow us to gain insights into the emotional journey undertaken by the characters in War and Peace.
…
Impressive work, even though I would not use it as a short-cut to “read a novel in record time.”
Rather I take this as an alternative way of reading War and Peace, one that can capture insights a casual reader may miss.
Moreover, the techniques demonstrated here could be used with other works of literature, or even non-fictional works.
Imagine conducting this analysis over the reportedly more than 7,000 page full CIA Torture Report, for example.
A heatmap does not connect any dots, but points a user towards places where interesting dots may be found.
Certainly a tool for exploring large releases/leaks of text data.
Enjoy!
PS: Large, tiresome, obscure-on-purpose, government reports to practice on with this method?