Data visualization: ambiguity as a fellow traveler by Vivien Marx. (Nature Methods 10, 613–615 (2013) doi:10.1038/nmeth.2530)
From the article:
Data from an experiment may appear rock solid. Upon further examination, the data may morph into something much less firm. A knee-jerk reaction to this conundrum may be to try and hide uncertain scientific results, which are unloved fellow travelers of science. After all, words can afford ambiguity, but with visuals, “we are damned to be concrete,” says Bang Wong, who is the creative director of the Broad Institute of MIT and Harvard. The alternative is to face the ambiguity head-on through visual means.
Color or color gradients in heat maps, for example, often show degrees of data uncertainty and are, at their core, visual and statistical expressions. “Talking about uncertainty is talking about statistics,” says Martin Krzywinski, whose daily task is data visualization at the Genome Sciences Centre at the British Columbia Cancer Agency.
Statistically driven displays such as box plots can work for displaying uncertainty, but most visualizations use more ad hoc methods such as transparency or blur. Error bars are also an option, but it is difficult to convey information clearly with them, he says. “It’s likely that if something as simple as error bars is misunderstood, anything more complex will be too,” Krzywinski says.
I don’t hear “ambiguity” and “uncertainty” as the same thing.
The duck/rabbit image you will remember from Sperberg-McQueen’s presentations is ambiguous, but not uncertain.
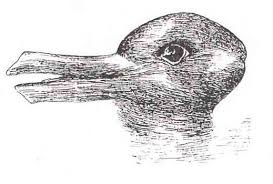
Granting that “uncertainty” and its visualization is a difficult task but let’s not compound the task by confusing it with ambiguity.
The uncertainty issue in this article echoes Steve Pepper’s concern over binary choices for type under the current TMDM. Either a topic, for example, is of a particular type or not. There isn’t any room for uncertainty.
The article has a number of suggestions on visualizing uncertainty that I think you may find helpful.
I first saw this at: Visualizing uncertainty still unsolved problem by Nathan Yau.
