A tweet I saw yesterday suggested surveilling U.S. concentration camps using a drone. That’s certainly possible but hobbyist type drones put you within easy visual distance of government forces. There are long range drones, all of which carry hefty price tags. What if you don’t have access to a long range drone? Alternatives?
Low-cost, low-tech answer: Consider the lowly helium balloon. With some experimenting, you can discover a stable buoyancy height for a ballon suitable for carrying a wireless digital camera.
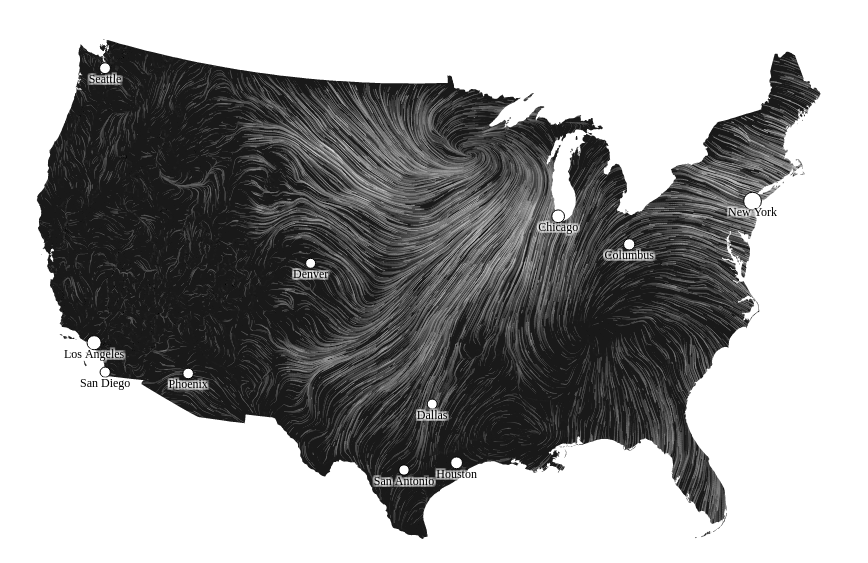
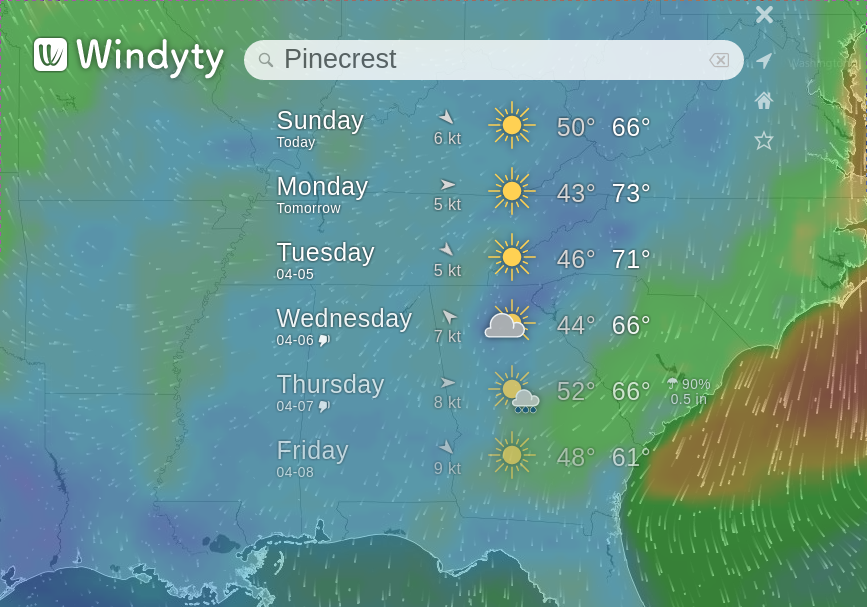
Unlike a short range drone, you can launch a balloon plus digital camera from random and distant locations from an actual concentration camp. Launch locations are chosen based on weaponizing weather data, made available by most governments. In the United States, the National Weather Service provides current wind data and maintains historical weather data.
Once you have a stable buoyancy height for your balloon plus digital camera (password protected), record the harness and camera weight so you can create other balloons to accompany the one or more balloons with cameras at a similar height. Authorities will go nuts trying to chase every balloon down as “evidence” and it creates opportunities for balloon spotters (BSers) to call in reports of balloon sightings and landings.
For surveillance purposes, use maps of wind conditions to select launch points that will result in your balloons passing over the concentration camps of interest. Concentration camps tend to be fixed locations and as you develop more experience with local wind patterns, the more successful you will be on a regular basis.
Perhaps old school but I would insure that every balloon has a physical limit to its travels. If you can’t think of any ways to do that, ask your former eight grade (US educational system) science teacher. That’s good for the environment. Should you find balloons released by others, remember that some devices bite upon discovery. Report discovered balloons to local law enforcement.
Balloons are cheap, annoying to government officials, and provide low-risk ways to document government activities, from rain forests to concentration camps. Weaponizing weather data for surveillance is only one way to use the common balloon. Other suggestions are forthcoming.
PS: Here is one list of U.S. concentration camps. I express no opinion about the accuracy of that list or the legality of surveilling any location mentioned therein. To avoid being U.S. specific, I’m happy to update this portion of the post with pointers to other lists of concentration camps around the world. Go carefully.