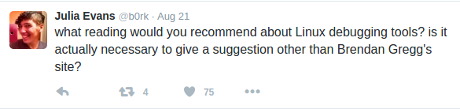
Julia Evans demonstrates how to get around the limits of Twitter and introduces you to a “starter network spy tool.”

A demonstration of her writing skills as well!
Ngrep at sourceforge.
Installing on Ubuntu 14.04:
sudo apt-get update
sudo apt-get install ngrep
I’m a follower of Julia’s but even so, I checked the man page for ngrep before running the example.
The command:
sudo ngrep -d any metafilter is interpreted:
sudo – runs ngrep as superuser (hence my caution)
ngrep – network grep
-d any – ngrep listens to “any” interface *
metafilter – match expression, packets that match are dumped.
* The “any” value following -d was the hardest value to track down. The man page for ngrep describes the -d switch this way:
-d dev
By default ngrep will select a default interface to listen on. Use this option to force ngrep to listen on interface dev.
Well, that’s less than helpful. 
Until you discover on the tcpdump man page:
–interface=interface
Listen on interface. If unspecified, tcpdump searches the system interface list for the lowest numbered, configured up interface (excluding loopback), which may turn out to be, for example, “eth0”.
On Linux systems with 2.2 or later kernels, an interface argument of “any” can be used to capture packets from all interfaces. Note that captures on the “any” device will not be done in promiscuous mode. (bold highlight added)
If you are running a Linux system with a 2.2 or later kernel, you can use the “any” argument to the interface -d switch of ngrep.
Understanding the entire command, I then felt safe running it as root. Not that I expected a bad outcome but I learned something in the process of researching the command.
Be aware that ngrep is a plethora of switches, options, bpf filters (Berkeley packet filters) and the like. The man page runs eight pages of, well, man page type material.
Enjoy!