Unmet Needs for Analyzing Biological Big Data: A Survey of 704 NSF Principal Investigators by Lindsay Barone, Jason Williams, David Micklos.
Abstract:
In a 2016 survey of 704 National Science Foundation (NSF) Biological Sciences Directorate principle investigators (BIO PIs), nearly 90% indicated they are currently or will soon be analyzing large data sets. BIO PIs considered a range of computational needs important to their work, including high performance computing (HPC), bioinformatics support, multi-step workflows, updated analysis software, and the ability to store, share, and publish data. Previous studies in the United States and Canada emphasized infrastructure needs. However, BIO PIs said the most pressing unmet needs are training in data integration, data management, and scaling analyses for HPC, acknowledging that data science skills will be required to build a deeper understanding of life. This portends a growing data knowledge gap in biology and challenges institutions and funding agencies to redouble their support for computational training in biology.
In particular, needs topic maps can address rank #1, #2, #6, #7, and #10, or as found by the authors:
…
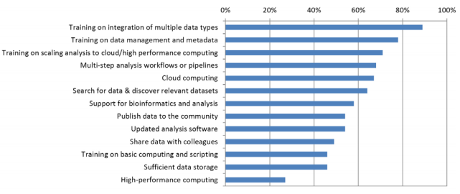
A majority of PIs—across bioinformatics/other disciplines, larger/smaller groups, and the four NSF programs—said their institutions are not meeting nine of 13 needs (Figure 3). Training on integration of multiple data types (89%), on data management and metadata (78%), and on scaling analysis to cloud/HP computing (71%) were the three greatest unmet needs. High performance computing was an unmet need for only 27% of PIs—with similar percentages across disciplines, different sized groups, and NSF programs.
…
or graphically (figure 3):
So, cloud, distributed, parallel, pipelining, etc., processing is insufficient?
Pushing undocumented and unintegratable data at ever increasing speeds is impressive but gives no joy?
This report will provoke another round of Esperanto fantasies, that is the creation of “universal” vocabularies, which if used by everyone and back-mapped to all existing literature, would solve the problem.
The number of Esperanto fantasies and the cost/delay of back-mapping to legacy data defeats all such efforts. Those defeats haven’t prevented repeated funding of such fantasies in the past, present and no doubt the future.
Perhaps those defeats are a question of scope.
That is rather than even attempting some “universal” interchange of data, why not approach it incrementally?
I suspect the PI’s surveyed each had some particular data set in mind when they mentioned data integration (which itself is a very broad term).
Why not seek out, develop and publish data integrations in particular instances, as opposed to attempting to theorize what might work for data yet unseen?
The need topic maps wanted to meet remains unmet. With no signs of lessening.
Opportunity knocks. Will we answer?