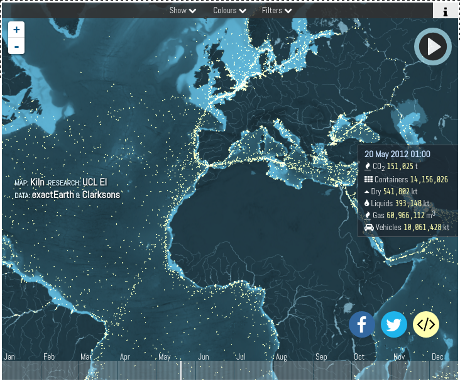
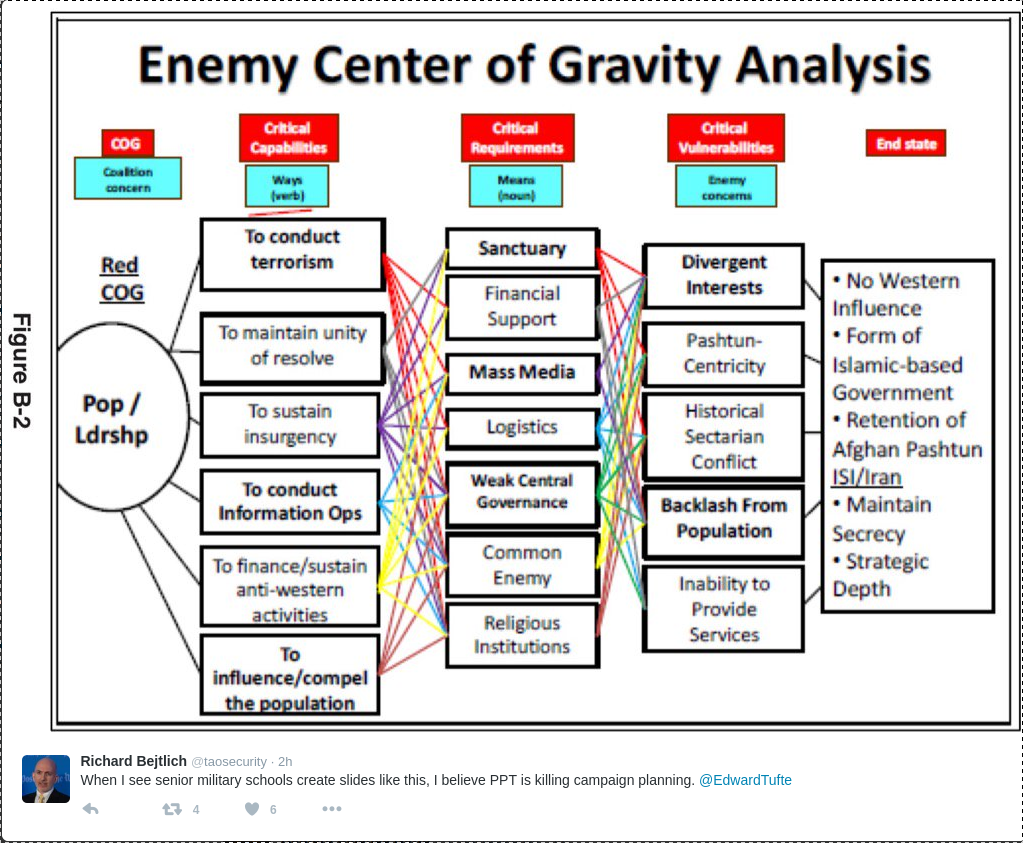
The Ethics of Data Analytics by Kaiser Fung.
Twenty-one slides on ethics by Kaiser Fung, author of: Junk Charts (data visualization blog), and Big Data, Plainly Spoken (comments on media use of statistics).
Fung challenges you to reach your own ethical decisions and acknowledges there are a number of guides to such decision making.
Unfortunately, Fung does not include professional responsibility requirements, such as the now out-dated Canon 7 of the ABA Model Code Of Professional Responsibility:
A Lawyer Should Represent a Client Zealously Within the Bounds of the Law
That canon has a much storied history, which is capably summarized in Whatever Happened To ‘Zealous Advocacy’? by Paul C. Sanders.
In what became known as Queen Caroline’s Case, the House of Lords sought to dissolve the marriage of King George the IV

to Queen Caroline

on the grounds of her adultery. Effectively removing her as queen of England.
Queen Caroline was represented by Lord Brougham, who had evidence of a secret prior marriage by King George the IV to Catholic (which was illegal), Mrs Fitzherbert.

Brougham’s speech is worth your reading in full but the portion most often cited for zealous defense reads as follows:
…
I once before took leave to remind your lordships — which was unnecessary, but there are many whom it may be needful to remind — that an advocate, by the sacred duty of his connection with his client, knows, in the discharge of that office, but one person in the world, that client and none other. To save that client by all expedient means — to protect that client at all hazards and costs to all others, and among others to himself — is the highest and most unquestioned of his duties; and he must not regard the alarm, the suffering, the torment, the destruction, which he may bring upon any other; nay, separating even the duties of a patriot from those of an advocate, he must go on reckless of the consequences, if his fate it should unhappily be, to involve his country in confusion for his client.
…
The name Mrs. Fitzherbert never slips Lord Brougham’s lips but the House of Lords has been warned that may not remain to be the case, should it choose to proceed. The House of Lords did grant the divorce but didn’t enforce it. Saving fact one supposes. Queen Caroline died less than a month after the coronation of George IV.
For data analysis, cybersecurity, or any of the other topics I touch on in this blog, I take the last line of Lord Brougham’s speech:
To save that client by all expedient means — to protect that client at all hazards and costs to all others, and among others to himself — is the highest and most unquestioned of his duties; and he must not regard the alarm, the suffering, the torment, the destruction, which he may bring upon any other; nay, separating even the duties of a patriot from those of an advocate, he must go on reckless of the consequences, if his fate it should unhappily be, to involve his country in confusion for his client.
as the height of professionalism.
Post-engagement of course.
If ethics are your concern, have that discussion with your prospective client before you are hired.
Otherwise, clients have goals and the task of a professional is how to achieve them. Nothing more.