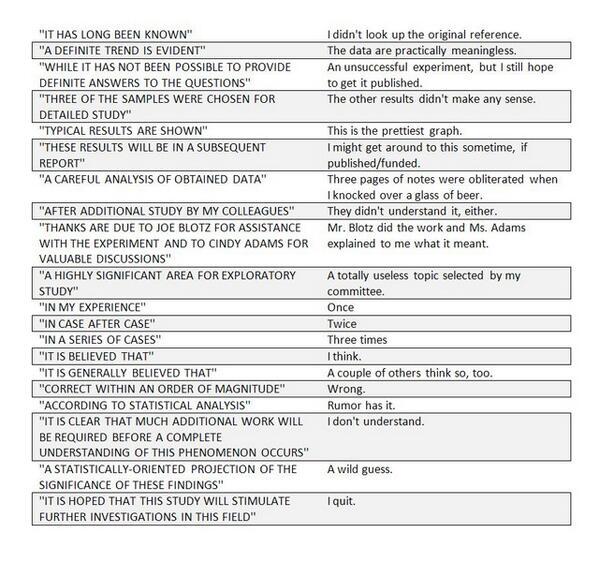
Interpretation Under Ambiguity by Peter Norvig.
From the paper:
Introduction
This paper is concerned with the problem of semantic and pragmatic interpretation of sentences. We start with a standard strategy for interpretation, and show how problems relating to ambiguity can confound this strategy, leading us to a more complex strategy. We start with the simplest of strategies:
|
Strategy 1: Apply syntactic rules to the sentence to derive a parse tree, then apply semantic rules to get a translation into some logical form, and finally do a pragmatic interpretation to arrive at the final meaning. |
Although this strategy completely ignores ambiguity, and is intended as a sort of strawman, it is in fact a commonly held approach. For example, it is approximately the strategy assumed by Montague grammar, where `pragmatic interpretation’ is replaced by `model theoretic interpretation.’ The problem with this strategy is that ambiguity can strike at the lexical, syntactic, semantic, or pragmatic level, introducing multiple interpretations. The obvious way to counter this problem is as follows:
|
Strategy 2: Apply syntactic rules to the sentence to derive a set of parse trees, then apply semantic rules to get a set of translations in some logical form, discarding any inconsistent formulae. Finally compute pragmatic interpretation scores for each possibility, to arrive at the `best’ interpretation (i.e. `most consistent’ or `most likely’ in the given context). |
In this framework, the lexicon, grammar, and semantic and pragmatic interpretation rules determine a mapping between sentences and meanings. A string with exactly one interpretation is unambiguous, one with no interpretation is anomalous, and one with multiple interpretations is ambiguous. To enumerate the possible parses and logical forms of a sentence is the proper job of a linguist; to then choose from the possibilities the one “correct” or “intended” meaning of an utterance is an exercise in pragmatics or Artificial Intelligence.
One major problem with Strategy 2 is that it ignores the difference between sentences that seem truly ambiguous to the listener, and those that are only found to be ambiguous after careful analysis by the linguist. For example, each of (1-3) is technically ambiguous (with could signal the instrument or accompanier case, and port could be a harbor or the left side of a ship), but only (3) would be seen as ambiguous in a neutral context.
(1) I saw the woman with long blond hair.
(2) I drank a glass of port.
(3) I saw her duck.
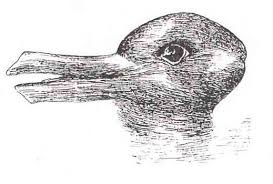
Lotfi Zadeh (personal communication) has suggested that ambiguity is a matter of degree. He assumes each interpretation has a likelihood score attached to it. A sentence with a large gap between the highest and second ranked interpretation has low ambiguity; one with nearly-equal ranked interpretations has high ambiguity; and in general the degree of ambiguity is inversely proportional to the sharpness of the drop-off in ranking. So, in (1) and (2) above, the degree of ambiguity is below some threshold, and thus is not noticed. In (3), on the other hand, there are two similarly ranked interpretations, and the ambiguity is perceived as such. Many researchers, from Hockett (1954) to Jackendoff (1987), have suggested that the interpretation of sentences like (3) is similar to the perception of visual illusions such as the Necker cube or the vase/faces or duck/rabbit illusion. In other words, it is possible to shift back and forth between alternate interpretations, but it is not possible to perceive both at once. This leads us to Strategy 3:
|
Strategy 3: Do syntactic, semantic, and pragmatic interpretation as in Strategy 2. Discard the low-ranking interpretations, according to some threshold function. If there is more than one interpretation remaining, alternate between them. |
Strategy 3 treats ambiguity seriously, but it leaves at least four problems untreated. One problem is the practicality of enumerating all possible parses and interpretations. A second is how syntactic and lexical preferences can lead the reader to an unlikely interpretation. Third, we can change our mind about the meaning of a sentence-“at first I thought it meant this, but now I see it means that.” Finally, our affectual reaction to ambiguity is variable. Ambiguity can go unnoticed, or be humorous, confusing, or perfectly harmonious. By `harmonious,’ I mean that several interpretations can be accepted simultaneously, as opposed to the case where one interpretation is selected. These problems will be addressed in the following sections.
…
Apologies for the long introduction quote but I want to entice you to read Norvig’s essay in full and if you have the time, the references that he cites.
It’s the literature you will have to master to use search engines and develop indexing strategies.
At least for one approach to search and indexing.
That within a language there is enough commonality for automated indexing or searching to be useful has been proven over and over again by Internet search engines.
But at the same time, the first twenty or so results typically leave you wondering what interpretation the search engine put on your words.
As I said, Peter’s approach is useful, at least for a first cut at search results.
The problem is that the first cut has become the norm for “success” of search results.
That works if I want to pay lawyers, doctors, teachers and others to find the same results as others have found before (past tense).
That cost doesn’t appear as a line item in any budget but repetitive “finding” of the same information over and over again is certainly a cost to any enterprise.
First cut on semantic interpretation, follow Norvig.
Saving re-finding costs and the cost of not-finding, requires something more robust than a one model to find words and in the search darkness bind them to particular meanings.
PS: See Peter@norvig.com for an extensive set of resources, papers, presentations, etc.
I first saw this in a tweet by James Fuller.