In a Twitter dust-up following The Privileged Cry: Boo, Hoo, Hoo Over Release of OnionScan Data the claim was made by [Λ•]ltSciFi@altscifi_that:
@SarahJamieLewis You take an ethical stance. @patrickDurusau does not. Note his regression to a childish tone. Also: schneier.com/blog/archives/…

To which I responded:
@altscifi_ @SarahJamieLewis Interesting. Questioning genuflection to privilege is a “childish tone?” Is name calling the best you can do?

Which earned this response from [Λ•]ltSciFi@altscifi_:
@patrickDurusau @SarahJamieLewis Not interested in wasting time arguing with you. Your version of “genuflection” doesn’t merit the effort.

Anything beyond name calling is too much effort for [Λ•]ltSciFi@altscifi_. Rather than admit they haven’t thought about the issue of the ethics of data access beyond “me too!,” it saves face to say discussion is a waste of time.
I have never denied that access to data can raise ethical issues or that such issues merit discussion.
What I do object to is that in such discussions, it has been my experience (important qualifier), that those urging ethics of data access have someone in mind to decide on data access. Almost invariably, themselves.
Take the recent “weaponized transparency” rhetoric of the Sunlight Foundation as an example. We can argue about the ethics of particular aspects of the DNC data leak, but the fact remains that the Sunlight Foundation considers itself, and not you, as the appropriate arbiter of access to an unfiltered version of that data.
I assume the Sunlight Foundation would include as appropriate arbiters many of the usual news organizations what accept leaked documents and reveal to the public only so much as they choose to reveal.
Not to pick on the Sunlight Foundation, there is an alphabet soup of U.S. government agencies that make similar claims of what should or should not be revealed to the public. I have no more sympathy for their claims of the right to limit data access than more public minded organizations.
Take the data dump of OnionScan data for example. Sarah Jamie Lewis may choose to help sites for victims of abuse (a good thing in my opinion) whereas others of us may choose to fingerprint and out government spy agencies (some may see that as a bad thing).
The point being that the OnionScan data dump enables more people to make those “ethical” choices and to not be preempted because data such as the OnionScan data should not be widely available.
BTW, in a later tweet Sarah Jamie Lewis says:
In which I am called privileged for creating an open source tool & expressing concerns about public deanonymization.

Missing the issue entirely as she was quoted as expressing concerns over the OnionScan data dump. Public deanonymization, is a legitimate concern so long as we all get to decide those concerns for ourselves. Lewis is trying to dodge the issue of her weak claim over the data dump for the stronger one over public deanonymization.
Unlike most of the discussants you will find, I don’t want to decide on what data you can or cannot see.
Why would I? I can’t foresee all uses and/or what data you might combine it with. Or with what intent?
If you consider the history of data censorship by governments, we haven’t done terribly well in our choices of censors or in the results of their censorship.
Let’s allow people to exercise their own sense of ethics. We could hardly do worse than we have so far.

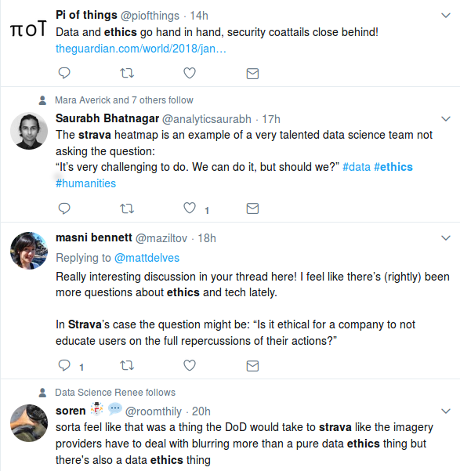

 . Or a bit larger:
. Or a bit larger: