Microsoft Security Risk Detection
From the webpage:
What is Microsoft Security Risk Detection?
Security Risk Detection is Microsoft’s unique fuzz testing service for finding security critical bugs in software. Security Risk Detection helps customers quickly adopt practices and technology battle-tested over the last 15 years at Microsoft.
“Million dollar” bugs
Security Risk Detection uses “Whitebox Fuzzing” technology which discovered 1/3rd of the “million dollar” security bugs during Windows 7 development.
Battle tested tech
The same state-of-the-art tools and practices honed at Microsoft for the last decade and instrumental in hardening Windows and Office — with the results to prove it.
Scalable fuzz lab in the cloud
One click scalable, automated, Intelligent Security testing lab in the cloud.
Cross-platform support
Linux Fuzzing is now available. So, whether you’re building or deploying software for Windows or Linux or both, you can utilize our Service.
…
No bug detection and/or fuzzing technique is 100%.
Here MS says for one product its “Whitebox Fuzzing” was 33% effective against “million dollar” security bugs.
A more meaningful evaluation of “Whitebox Fuzzing” would be to say which of the 806 Windows 7 vulnerabilities listed at CVE Details were detected and which ones were not.
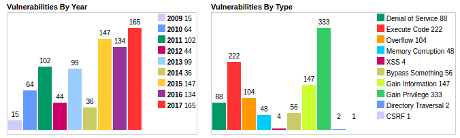
I don’t know your definition of a “million dollar” security bugs so statistics against known bugs would be more meaningful.
Yes?
