Using Gephi 8.2, you can create graphs of the Clinton/Podesta emails based on terms in subject lines or the body of the emails. You can interactively work with all 30K+ (as of today) emails and extract networks based on terms in the posts. No programming required. (Networks based on terms will appear tomorrow.)
If you have Gephi 8.2 (I can’t find the import spigot in 9.0 or 9.1), you can import the Clinton/Podesta Emails (1-18) for analysis as a network.
To save you the trouble of regressing to Gephi 8.2, I performed a no frills/default import and exported that file as podesta-1-18-network.gephi.gz.
Download and uncompress podesta-1-18-network.gephi.gz, then you can pickup at timemark 3.49.
Open the file (your location may differ):
Obligatory hair-ball graph visualization. 

Considerably less appealing that Jennifer Golbeck’s but be patient!
First step, Layout -> Yifan Hu. My results:

Second step, Network Diameter statistics (right side, run).
No visible impact on the graph but, now you can change the color and size of nodes in the graph. That is they have attributes on which you can base the assignment of color and size.
Tutorial gotcha: Not one of Jennifer’s tutorials but I was watching a Gephi tutorial that skipped the part about running statistics on the graph prior to assignment of color and size. Or I just didn’t hear it. The menu options appear in documentation but you can’t access them unless and until you run network statistics or have attributes for the assignment of color and size. Run statistics first!
Next, assign colors based on betweenness centrality:
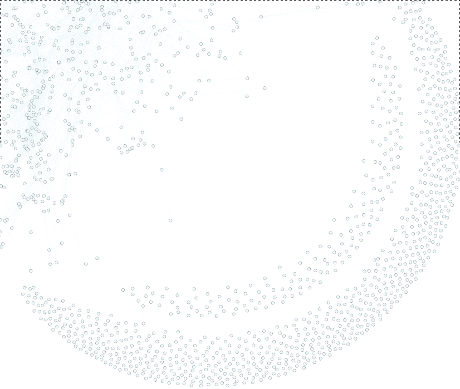
The densest node is John Podesta, but if you remove his node, rerun the network statistics and re-layout the graph, here is part of what results:
A no frills import of 31,819 emails results in a graph of 3235 nodes and 11,831 edges.
That’s because nodes and edges combine (merge to you topic map readers) when they have the same identifier or for edges are between the same nodes.
Subject to correction, when that combining/merging occurs, the properties on the respective nodes/edges are accumulated.
Topic mappers already realize there are important subjects missing, some 31,819 of them. That is the emails themselves don’t by default appear as nodes in the network.
Ian Robinson, Jim Webber & Emil Eifrem illustrate this lossy modeling in Graph Databases this way:
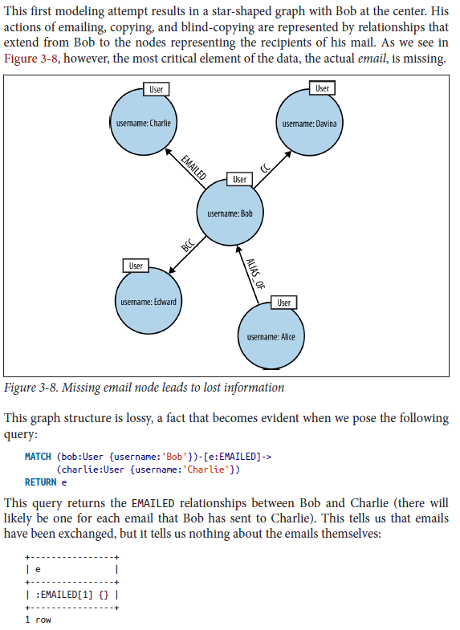
Modeling emails without the emails is rather lossy.
Other nodes/subjects we might want:
- Multiple to: emails – Is who was also addressed important?
- Multiple cc: emails – Same question as with to:.
- Date sent as properties? So evolution of network/emails can be modeled.
- Capture “reply-to” for relationships between emails?
Other modeling concerns?
Bear in mind that we can suppress a large amount of the detail so you can interactively explore the graph and only zoom into/display data after finding interesting patterns.
Some helpful links:
https://archive.org/details/PodestaEmailszipped: The email collection as bulk download, thanks to Michael Best, @NatSecGeek.
https://github.com/gephi/gephi/releases: Where you can grab a copy of Gephi 8.2.