Our World in Data by Mike Roser.
Visualizations of War & Violence, Global Health, Africa, World Poverty and World Hunger & Food Provision.
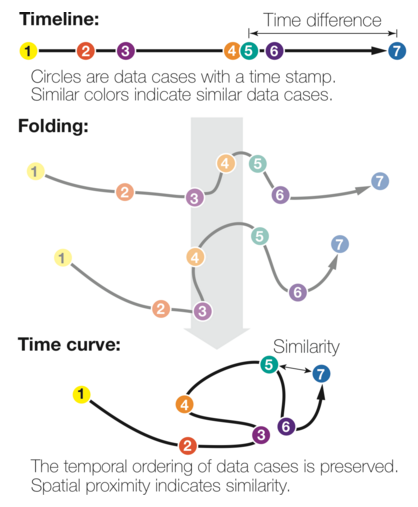
An author chooses their time period but I find limiting the discussion of world poverty to the last 2,000 years problematic. Obtaining even projected data would be problematic but we know there were civilizations, particularly in the Ancient Near East and in Pre-Columbian America that had rather high standards of living. For that matter, for the time period given, the poverty map skips over the Roman Empire at its height, saying “we know that every country was extremely poor compared to modern living standards.”
The Romans had public bath houses, running water, roads that we still use today, public entertainment, libraries, etc. I am not sure how they were “extremely poor compared to modern living conditions.”
It is also problematic (slide 12) when Max says that:
Before modern economic growth the huge majority lived in extreme poverty and only a tiny elite enjoyed a better standard of living.
There are elites in every society that live better than most but that doesn’t automatically imply that over 84% to 94% of the world population was living in poverty. You don’t sustain a society such as the Aztecs or the Incas with only 6 to 16% of the population living outside poverty.
I am deeply doubtful of Max’s conclusion that in terms of poverty the world is becoming more “equal.”
Part of that skepticism is from being aware of statistics like:
“With less than 5 percent of world population, the U.S. uses one-third of the world’s paper, a quarter of the world’s oil, 23 percent of the coal, 27 percent of the aluminum, and 19 percent of the copper,” he reports. “Our per capita use of energy, metals, minerals, forest products, fish, grains, meat, and even fresh water dwarfs that of people living in the developing world.”
Use It and Lose It: The Outsize Effect of U.S. Consumption on the Environment
Considering that many of those resources are not renewable, there is a natural limit to how much improvement can or will take place outside of the United States. When renewable resources become more practical than they are today, they will only supplement the growing consumption of energy in the United States, not replace it.
Max provides access to his data sets if you are interested in exploring the data further. I would be extremely careful with his World Bank data because the World Bank does have an agenda to show the benefits of development across the world.
Considering the impact of consumption on the environment, the World Bank’s pursuit of a global consumption economy may be one of the more ill-fated schemes of all time.
If you are interested in this type of issue, the National Geographic’s Greendex may be of interest.