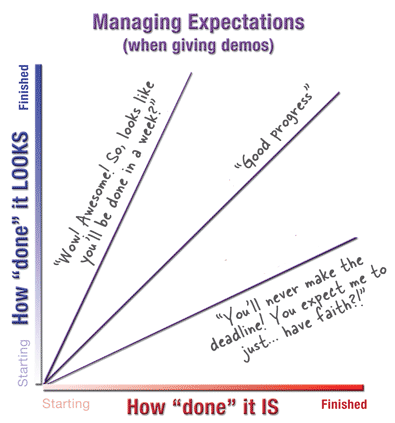
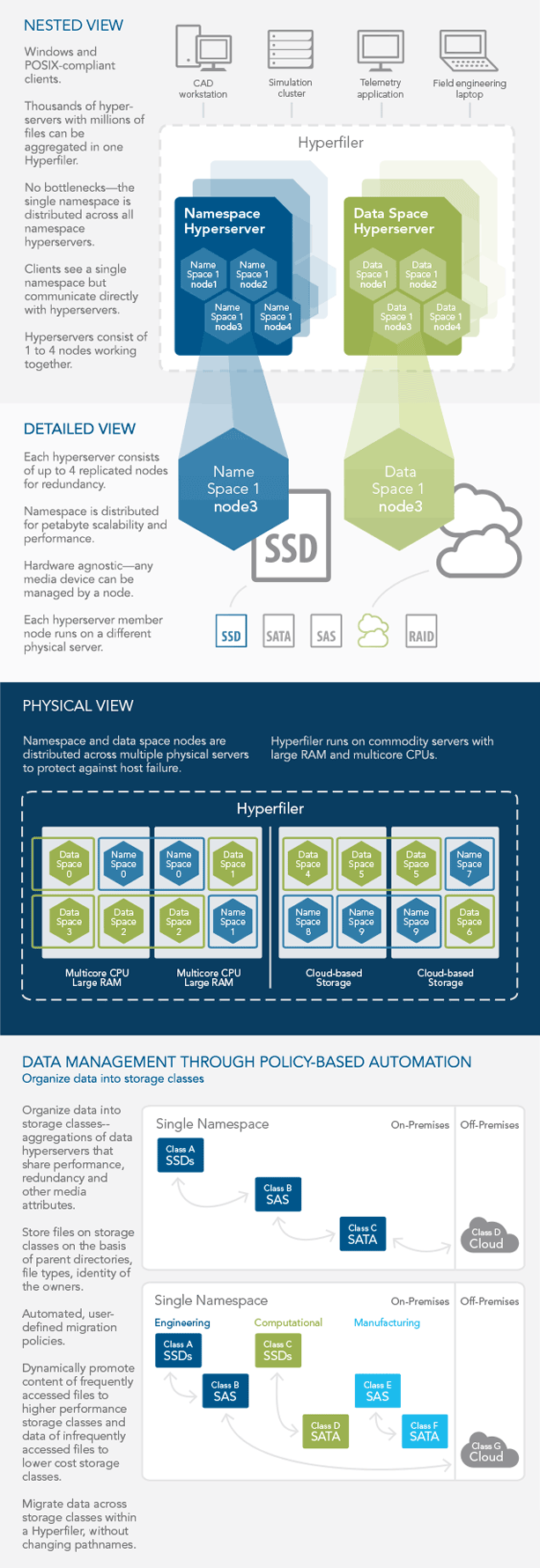
Fixing Pentagon Intelligence by John R. Schindler.
From the post:
The U.S. Intelligence Community (IC), that vast agglomeration of seventeen different hush-hush agencies, is an espionage behemoth without peer anywhere on earth in terms of budget and capabilities. Fully eight of those spy agencies, plus the lion’s share of the IC’s budget, belong to the Department of Defense (DoD), making the Pentagon’s intelligence arm something special. It includes the intelligence agencies of all the armed services, but the jewel in the crown is the National Security Agency (NSA), America’s “big ears,” with the National Geospatial-Intelligence Agency (NGA), which produces amazing imagery, following close behind.
None can question the technical capabilities of DoD intelligence, but do the Pentagon’s spies actually know what they are talking about? This is an important, and too infrequently asked, question. Yet it was more or less asked this week, in a public forum, by a top military intelligence leader. The venue was an annual Washington, DC, intelligence conference that hosts IC higher-ups while defense contractors attempt a feeding frenzy, and the speaker was Rear Admiral Paul Becker, who serves as the Director of Intelligence (J2) on the Joint Chiefs of Staff (JCS). A career Navy intelligence officer, Becker’s job is keeping the Pentagon’s military bosses in the know on hot-button issues: it’s a firehose-drinking position, made bureaucratically complicated because JCS intelligence support comes from the Defense Intelligence Agency (DIA), which is an all-source shop that has never been a top-tier IC agency, and which happens to have some serious leadership churn at present.
Admiral Becker’s comments on the state of DoD intelligence, which were rather direct, merit attention. Not surprisingly for a Navy guy, he focused on China. He correctly noted that we have no trouble collecting the “dots” of (alleged) 9/11 infamy, but can the Pentagon’s big battalions of intel folks actually derive the necessary knowledge from all those tasty SIGINT, HUMINT, and IMINT morsels? Becker observed — accurately — that DoD intelligence possesses a “data glut but an information deficit” about China, adding that “We need to understand their strategy better.” In addition, he rued the absence of top-notch intelligence analysts of the sort the IC used to possess, asking pointedly: “Where are those people for China? We need them.”
…
Admiral Becker’s:
“data glut but an information deficit” (emphasis added)
captures the essence of phone record subpoenas, mass collection of emails, etc., all designed to give the impression of frenzied activity, with no proof of effectiveness. That is an “information deficit.”
Be reassured you can host a data glut in a topic map so topic maps per se are not a threat to current data gluts. It is possible, however, to use topic maps over existing data gluts to create information and actionable intelligence. Without disturbing the underlying data gluts and their contractors.
I tried to find a video of Adm. Becker’s presentation but apparently the Intelligence and National Security Security Summit 2014 does not provide video recording of presentations. Whether that is to prevent any contemporaneous record being kept of remarks or just being low-tech kinda folks isn’t clear.
I can point out the meeting did have a known liar, “The Honorable James Clapper,” on the agenda. Hard to know if having perjured himself in front of Congress has made him gun shy of recorded speeches or not. (For Clapper’s latest “spin,” on “the least untruthful,” see: James Clapper says he misspoke, didn’t lie about NSA surveillance.) One hopes by next year’s conference Clapper will appear as: James Clapper, former DNI, convicted felon, Federal Prison Register #….
If you are interested in intelligence issues, you should be following John R. Schindler. A U.S. perspective but handling issues in intelligence with topic maps will vary in the details but not the underlying principles from one intelligence service to another.
Disclosure: I rag on the intelligence services of the United States due to greater access to public information on those services. Don’t take that as greater interest how their operations could be improved by topic maps over other intelligence services.
I am happy to discuss how your intelligence services can (or can’t) be improved by topic maps. There are problems, such as those discussed by Admiral Becker, that can’t be fixed by using topic maps. I will be as quick to point those out as I will problems where topic maps are relevant. My goal is your satisfaction that topic maps made a difference for you, not having a government entity in a billing database.