Peaxy Hyperfiler Redefines Data Management to Deliver on the Promise of Advanced Analytics
From the post:
Peaxy, Inc. (www.peaxy.net) today announced general availability of the Peaxy Hyperfiler, its hyperscale data management system that enables enterprises to access and manage massive amounts of unstructured data without disrupting business operations. For engineers and researchers who must search for datasets across multiple geographies, platforms and drives, accessing all the data necessary to inform the product lifecycle, from design to predictive maintenance, presents a major challenge. By making all data, regardless of quantity or location, immediately accessible via a consistent data path, companies will be able to dramatically accelerate their highly technical, data-intensive initiatives. These organizations will be able to manage data in a way that allows them to employ advanced analytics that have been promised for years but never truly realized.
…
…Key product features include:
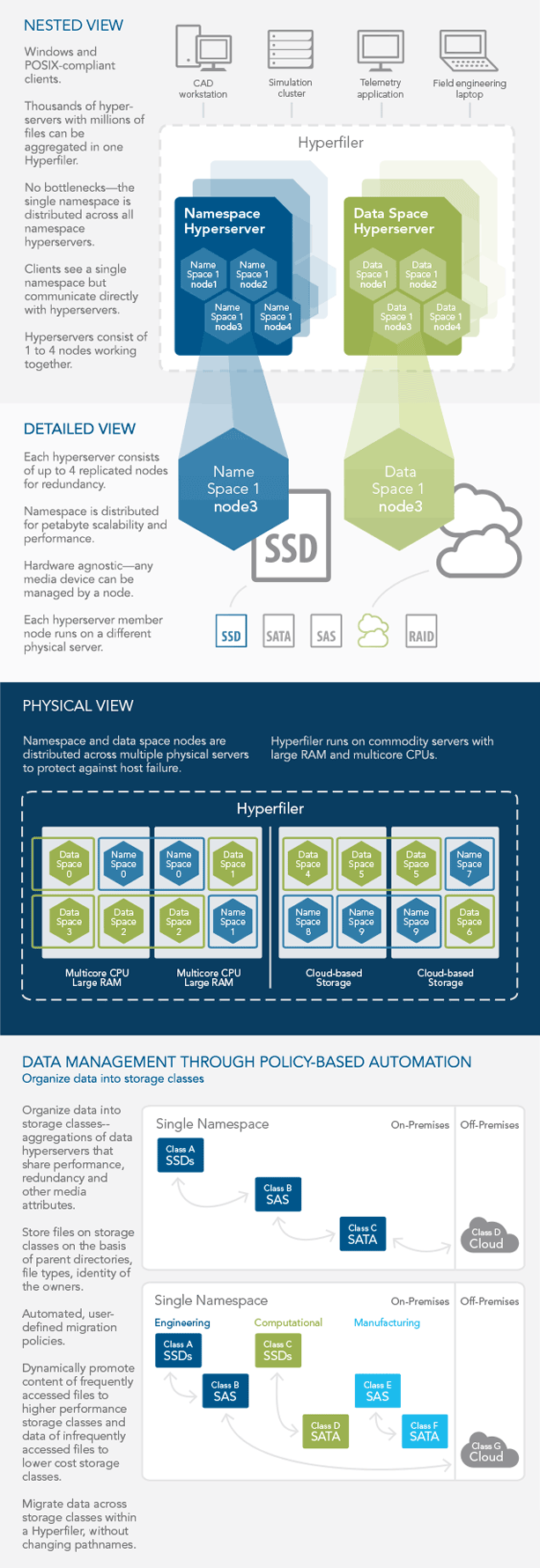
- Scalability to tens of thousands of nodes enabling the creation of an exabyte-scale data infrastructure in which performance scales in parallel with capacity
- Fully distributed namespace and data space that eliminate data silos to make all data easily accessible and manageable
- Simple, intuitive user interface built for engineers and researchers as well as for IT
- Data tiered in storage classes based on performance, capacity and replication factor
- Automated, policy-based data migration
- Flexible, customizable data management
- Remote, asynchronous replication to facilitate disaster recovery
- Call home remote monitoring
- Software-based, hardware-agnostic architecture that eliminates proprietary lock-in
- Addition or replacement of hardware resources with no down time
- A version of the Hyperfiler that has been successfully beta tested on Amazon Web Services (AWS)
I would not say that the “how it works” page is opaque but it does remind me of the Grinch telling Cindy Lou that he was taking their Christmas tree to be repaired. Possible but lacking in detail.
What do you think?
Do you see:
- Any mention of mapping multiple sources of data into a consolidated view?
- Any mention of managing changing terminology over a product history?
- Any mention of indexing heterogeneous data?
- Any mention of natural language processing unstructured data?
- Any mention of machine learning over unstructured data?
- Anything beyond am implied “a miracle” occurs between data and Hyperfiler?
The documentation promises “data filters” but is also short on specifics.
A safe bet that mapping of terminology and semantics, for an enterprise and/or long product history, remains fertile ground for topic maps.
I first saw this in a tweet by Gregory Piatetsky
PS: Answers to the questions I raise may exist somewhere but I warrant they weren’t posted on September 29, 2014 at the locations listed in this post.