If you are following the Middle East, no doubt you have heard that ISIS/ISIL publishes Dabiq, a magazine that promotes its views. It isn’t hard to find articles quoting from Dabiq, but I wanted to find copies of Dabiq itself.
Clarion Project (Secondary Source for Dabiq)
After a bit of searching, I found that the Clarion Project is posting every issue of Dabiq as it appears.
The hosting site, Clarion Project, is a well known anti-Muslim hate group. The founders of the Clarion Project just happened to be full time employees of Aish Hatorah, a pro-Israel organization.
Coverage of Dabiq by Mother Jones (who should know better), ISIS Magazine Promotes Slavery, Rape, and Murder of Civilians in God’s Name relies on The Clarion Project “reprint” of Dabiq.
Internet Archive (Secondary Source for Dabiq)
The Islamic State Al-Hayat Media Centre (HMC) presents Dabiq Issue #1 (July 5, 2014).
All the issues at the Internet Archive claim to be from: “The Islamic State Al-Hayat Media Centre (HMC). I say “claim to be from” because uploading to the Internet Archive only requires an account with a verified email address. Anyone could have uploaded the documents.
Robert Mackey writes for the New York Times: Islamic State Propagandists Boast of Sexual Enslavement of Women and Girls and references Dabiq. I asked Robert for his source for Dabiq and he responded that it was the Internet Archive version.
Wall Street Journal
In Why the Islamic State Represents a Dangerous Turn in the Terror Threat, Gerald F. Seib writes:
It isn’t necessary to guess at what ISIS is up to. It declares its aims, tactics and religious rationales boldly, in multiple languages, for all the world to see. If you want to know, simply call up the first two editions of the organization’s remarkably sophisticated magazine, Dabiq, published this summer and conveniently offered in English online.
Gerald implies, at least to me, that Dabiq has a “official” website where it appears in multiple languages. But if you read Gerald’s article, there is no link to such a website.
I wrote to Gerald today to ask what site he meant when referring to Dabiq. I have not heard back from Gerald as of posting but will insert his response when it arrives.
The Jamestown Foundation
The Jamestown Foundation website featured: Hot Issue: Dabiq: What Islamic State’s New Magazine Tells Us about Their Strategic Direction, Recruitment Patterns and Guerrilla Doctrine by Michael W. S. Ryan, saying:
On the first day of Ramadan (June 28), the Islamic State in Iraq and Syria (ISIS) declared itself the new Islamic State and the new Caliphate (Khilafah). For the occasion, Abu Bakr al-Baghdadi, calling himself Caliph Ibrahim, broke with his customary secrecy to give a surprise khutbah (sermon) in Mosul before being rushed back into hiding. Al-Baghdadi’s khutbah addressed what to expect from the Islamic State. The publication of the first issue of the Islamic State’s official magazine, Dabiq, went into further detail about the Islamic State’s strategic direction, recruitment methods, political-military strategy, tribal alliances and why Saudi Arabia’s concerns that the Kingdom may be the Islamic State’s next target are well-founded.
Which featured a thumbnail of the cover of the first issue of Dabiq, with the following legend:
Dabiq Magazine (Source: Twitter user @umOmar246)
Well, that’s a problem because the Twitter user “@umOmar246” doesn’t exist.
Don’t take my word for it, go to Twitter, search for “umOmar246,” limit search results to people and you will see:
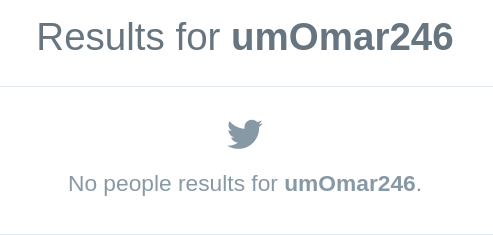
I took the screen shot today just in case the results change at some point in time.
Other Media
Other media carry the same stories but without even attempting to cite a source. For example:
Jerusalem Post: ISIS threatens to conquer the Vatican, ‘break the crosses of the infidels’. Source? None.
Global News: The twisted view of ISIS in latest issue of propaganda magazine Dabiq by Nick Logan.
I don’t think that Nick appreciates the irony of the title of his post. Yes, this is a twisted view of ISIS. The question is who is responsible for it?
General Comments
Pick any issue of Dabiq and skim through it. What impressed me was the “over the top” presentation of cruelty. The hate literature I am familiar with (I grew up in the Deep South in the 1960’s) usually portrays the atrocities of others, not the group in question. Hate literature places its emphasis on the “other” group, the one to be targeted, not itself.
Analysis
First and foremost, the lack of any “official” site of origin for Dabiq makes me highly suspicious of the authenticity of the materials that claim to originate with ISIS.
Second, why would ISIS rely upon the Clarion Project as a distributor for its English language version of Dabiq, along with the Internet Archive?
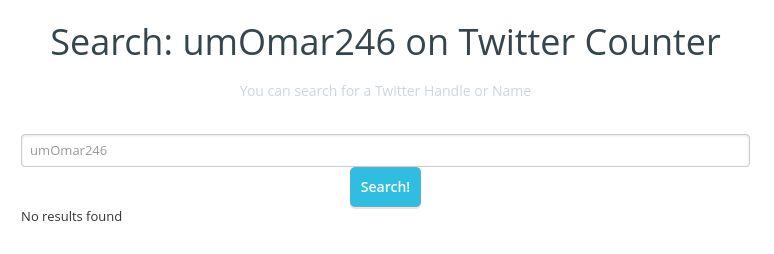
Third, what are we to make of missing @umOmar246 from Twitter? Before you say that the account has closed, http://twittercounter.com/
doesn’t know that user either:
A different aspect of consistency on distributed data. The aspect of getting “caught” because distributed data is difficult to make consistent.
Fourth, the media coverage examined relies upon sites with questionable authenticity but cites the material found there as though authoritative. Is this a new practice in journalism? Some of the media outlets examined are hardly new and upcoming Internet news sites.
Finally, the content of the magazines themselves don’t ring true for hate literature.
Conclusion
Debates about international and national policy should not be based on faked evidence (such as “yellow cake uranium“) or faked publications.
Based on what I have uncovered so far, attributing Dabiq to ISIS is highly questionable.
It appears to be an attempt to discredit ISIS and to provide a basis for whipping up support for military action by the United States and its allies.
The United States destroyed the legitimate government of Iraq on the basis of lies and fabrications. If only for nationalistic reasons, not spending American funds and lives based on a tissue of lies, let’s not make the same mistake again.
Disclaimer: I am not a supporter of ISIS nor would I choose to live in their state should they establish one. However, it will be their state and I lack the arrogance to demand that others follow social, religious or political norms that I prefer.
PS: If you have suggestions for other factors that either confirm a link between ISIS and Dabiq or cast further doubt on such a link, please post them in comments. Thanks!