This week we have covered:
- Fact Checking Wikileaks’ Vault 7: CIA Hacking Tools Revealed (Part 1) Eliminated duplication and editorial artifacts, 1134 HTML files out of 7809 remain.
- Fact Checking Wikileaks’ Vault 7: CIA Hacking Tools Revealed (Part 2 – The PDF Files) Eliminated public and placeholder documents, 114 arguably CIA files remain.
- CIA Documents or Reports of CIA Documents? Vault7 All of the HTML files are reports of possibly CIA material but we do know HTML file != CIA document.
- Boiling Reports of CIA Documents (Wikileaks CIA Vault 7 CIA Hacking Tools Revealed) The HTML files contain a large amount of cruft, which can be extracted using XQuery and common tools.
Interesting, from a certain point of view, but aside from highlighting bloated leaking from Wikileaks, why should anyone care?
Good question!
Let’s compare the de-duped but raw with the de-duped but boiled document set.
De-duped but raw document set:
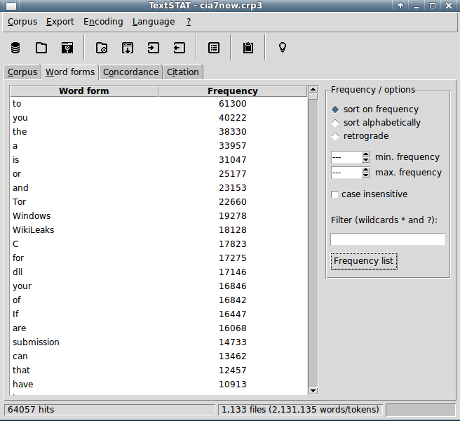
De-duped and boiled document set:

In raw count, boiling took us from 2,131,135 words/tokens to 665,202 words/tokens.
Here’s a question for busy reporters/researchers:
Has the CIA compromised the Tor network?
In the raw files, Tor occurs 22660 times.
In the boiled files, Tor occurs 4 times.
Here’s a screen shot of the occurrences:
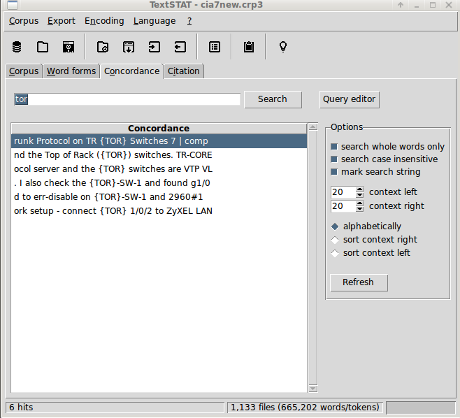
With TextSTAT, select the occurrence in the concordance and another select (mouse click to non-specialists) takes you to:
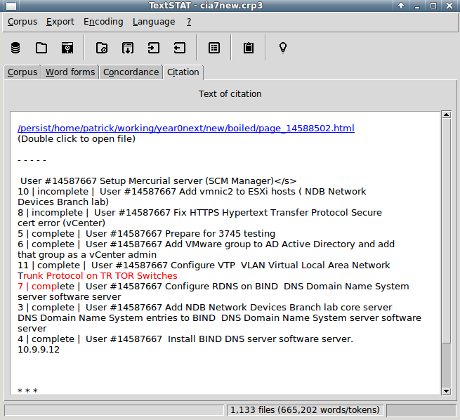
In a matter of seconds, you can answer as far as the HTML documents of Vault7 Part1 show, the CIA is talking about top of rack (ToR), a switching architecture for networks. Not, the Tor Project.
What other questions do you want to pose to the boiled Vault 7: CIA Hacking Tools Revealed document set?
Tooling up for efficient queries
First, you need: Boiled Content of Unique CIA Vault 7 Hacking Tools Revealed Files.
Second, grab a copy of: TextSTAT – Simple Text Analysis Tool runs on Windows, GNU/Linux and MacOS. (free)
When you first open TextSTAT, it will invite you to create a copora.

The barrel icon to the far left creates a new corpora. Select it and:
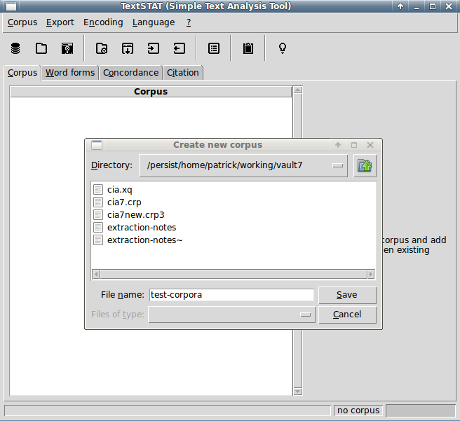
Once you save the new corpora, this reminder about encodings pops up:
I haven’t explored loading Windows files while on a Linux box but will and report back. Interesting to see inclusion of PDF. Something we need to explore after we choose which of the 124 possibly CIA PDF files to import.
Finally, you are at the point of navigating to where you have stored the unzipped Boiled Content of Unique CIA Vault 7 Hacking Tools Revealed Files:
Select the first file, scroll to the end of the list, press shift and select the last file. Then choose OK. It takes a minute or so to load but it has a progress bar to let you know it is working.
Observations on TextSTAT
As far as I can tell, TextSTAT doesn’t use the traditional stop list of words but enables you to set of maximum and minimum occurrences in the Word Form window. Along with wildcards as well. More flexible than the old stop list practice.
BTW, the context right/left on the Concordance window refers to characters, not words/tokens. Another departure from my experience with concordances. Not a criticism, just an observation of something that puzzled me at first.
Conclusion
The benefit of making secret information available, a la Wikileaks cannot be over-stated.
But making secret information available isn’t the same as making it accessible.
Investigators, reporters, researchers, the oft-mentioned public, all benefit from accessible information.
Next week look for a review of the probably CIA PDF files to see which ones I would incorporate into the corpora. (You may include more or less.)
PS: I’m looking for telecommuting work, editing, research (see this blog), patrick@durusau.net.
[…] http://tm.durusau.net/?p=74590 […]
Pingback by Daily Reading #94 | thinkpatriot — March 25, 2017 @ 9:20 am