EDAM: an ontology of bioinformatics operations, types of data and identifiers, topics and formats by Jon Ison, Matúš Kalaš, Inge Jonassen, Dan Bolser, Mahmut Uludag, Hamish McWilliam, James Malone, Rodrigo Lopez, Steve Pettifer and Peter Rice. (Bioinformatics (2013) 29 (10): 1325-1332. doi: 10.1093/bioinformatics/btt113)
Abstract:
Motivation: Advancing the search, publication and integration of bioinformatics tools and resources demands consistent machine-understandable descriptions. A comprehensive ontology allowing such descriptions is therefore required.
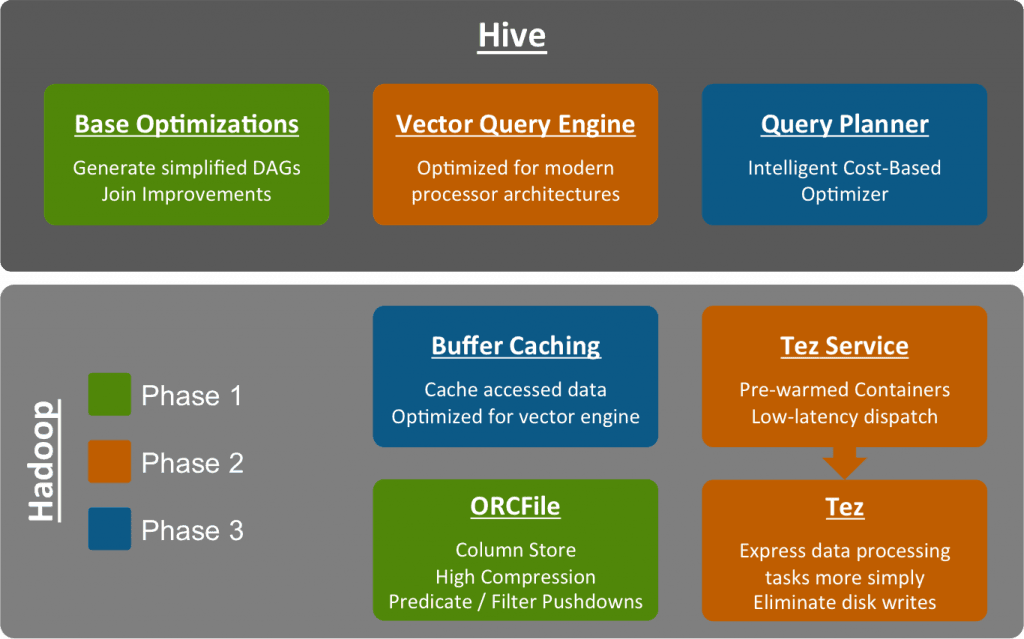
Results: EDAM is an ontology of bioinformatics operations (tool or workflow functions), types of data and identifiers, application domains and data formats. EDAM supports semantic annotation of diverse entities such as Web services, databases, programmatic libraries, standalone tools, interactive applications, data schemas, datasets and publications within bioinformatics. EDAM applies to organizing and finding suitable tools and data and to automating their integration into complex applications or workflows. It includes over 2200 defined concepts and has successfully been used for annotations and implementations.
Availability: The latest stable version of EDAM is available in OWL format from http://edamontology.org/EDAM.owl and in OBO format from http://edamontology.org/EDAM.obo. It can be viewed online at the NCBO BioPortal and the EBI Ontology Lookup Service. For documentation and license please refer to http://edamontology.org. This article describes version 1.2 available at http://edamontology.org/EDAM_1.2.owl.
No matter how many times I read it, I just don’t get:
Advancing the search, publication and integration of bioinformatics tools and resources demands consistent machine-understandable descriptions. A comprehensive ontology allowing such descriptions is therefore required.
I will be generous and assume the authors meant “machine-processable descriptions” when I read “machine-understandable descriptions.” It is well known that machines don’t “understand” data, they simply process it according to specified instructions.
But more to the point, machines are indifferent to the type or number of descriptions they have for any subject. It might confuse a human processor to have thirty (30) different descriptions for the same subject but there has been no showing of such a limit for machines.
Every effort to produce a “comprehensive” ontology/classification/taxonomy, pick your brand of poison, has been in the face of competing and different descriptions. That is, after all, the rationale for a comprehensive …, that there are too many choices already.
The outcome of all such efforts, assuming there are N diverse descriptions is N + 1 diverse descriptions, the 1 being the current project added to existing diverse descriptions.