Basel Committee issues “Principles for effective risk data aggregation and risk reporting – final document”
Not a very inviting title is it? 😉
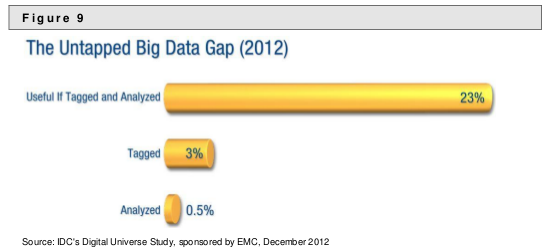
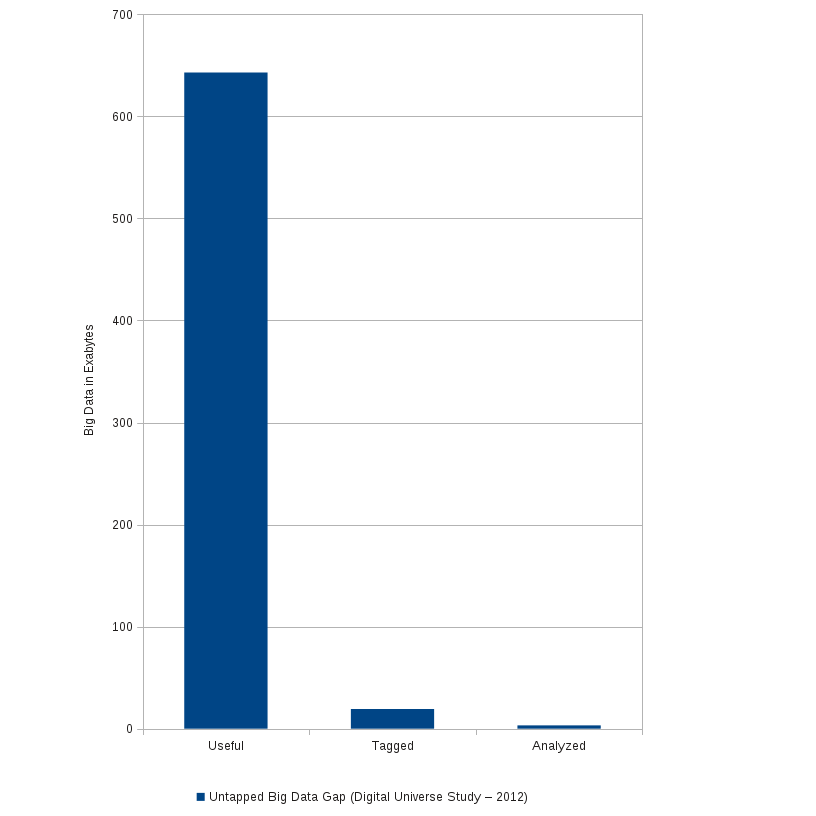
Still, the report is important for banks, enterprises in general (if you take out the “r” word) and illustrates the need for topic maps.
From the post:
The Basel Committee on Banking Supervision today issued Principles for effective risk data aggregation and risk reporting.
The financial crisis that began in 2007 revealed that many banks, including global systemically important banks (G-SIBs), were unable to aggregate risk exposures and identify concentrations fully, quickly and accurately. This meant that banks’ ability to take risk decisions in a timely fashion was seriously impaired with wide-ranging consequences for the banks themselves and for the stability of the financial system as a whole.
The report goes into detail but the crux of the problem is contained in: “…were unable to aggregate risk exposures and identify concentrations fully, quickly and accurately.”
Easy said than fixed but the critical failure was the inability to reliable aggregate data. (Where have you heard that before?)
Principles for effective risk data aggregation and risk reporting (full text) is only twenty-eight (28) pages and worth reading in full.
Of the fourteen (14) principles, seven (7) of them could be directly advanced by the use of topic maps:
Principle 2 Data architecture and IT infrastructure – A bank should design, build and maintain data architecture and IT infrastructure which fully supports its risk data aggregation capabilities and risk reporting practices not only in normal times but also during times of stress or crisis, while still meeting the other Principles….
33. A bank should establish integrated 16 data taxonomies and architecture across the banking group, which includes information on the characteristics of the data (metadata), as well as use of single identifiers and/or unified naming conventions for data including legal entities, counterparties, customers and accounts.
16 Banks do not necessarily need to have one data model; rather, there should be robust automated reconciliation procedures where multiple models are in use.
Principle 3 Accuracy and Integrity – A bank should be able to generate accurate and reliable risk data to meet normal and stress/crisis reporting accuracy requirements. Data should be aggregated on a largely automated basis so as to minimise the probability of errors….
As a precondition, a bank should have a “dictionary” of the concepts used, such that data is defined consistently across an organisation. [What about across banks/sources?]
Principle 4 Completeness – A bank should be able to capture and aggregate all material risk data across the banking group. Data should be available by business line, legal entity, asset type, industry, region and other groupings, as relevant for the risk in question, that permit identifying and reporting risk exposures, concentrations and emerging risks….
A banking organisation is not required to express all forms of risk in a common metric or basis, but risk data aggregation capabilities should be the same regardless of the choice of risk aggregation systems implemented. However, each system should make clear the specific approach used to aggregate exposures for any given risk measure, in order to allow the board and senior management to assess the results properly.
Principle 5 Timeliness – A bank should be able to generate aggregate and up-to-date risk data in a timely manner while also meeting the principles relating to accuracy and integrity, completeness and adaptability. The precise timing will depend upon the nature and potential volatility of the risk being measured as well as its criticality to the overall risk profile of the bank. The precise timing will also depend on the bank-specific frequency requirements for risk management reporting, under both normal and stress/crisis situations, set based on the characteristics and overall risk profile of the bank….
The Basel Committee acknowledges that different types of data will be required at different speeds, depending on the type of risk, and that certain risk data may be needed faster in a stress/crisis situation. Banks need to build their risk systems to be capable of producing aggregated risk data rapidly during times of stress/crisis for all critical risks.
Principle 6 Adaptability – A bank should be able to generate aggregate risk data to meet a broad range of on-demand, ad hoc risk management reporting requests, including requests during stress/crisis situations, requests due to changing internal needs and requests to meet supervisory queries….
(a) Data aggregation processes that are flexible and enable risk data to be aggregated for assessment and quick decision-making;
(b) Capabilities for data customisation to users’ needs (eg dashboards, key takeaways, anomalies), to drill down as needed, and to produce quick summary reports;
[Flexible merging and tracking sources through merging.]
Principle 7 Accuracy – Risk management reports should accurately and precisely convey aggregated risk data and reflect risk in an exact manner. Reports should be reconciled and validated….
(b) Automated and manual edit and reasonableness checks, including an inventory of the validation rules that are applied to quantitative information. The inventory should include explanations of the conventions used to describe any mathematical or logical relationships that should be verified through these validations or checks; and
(c) Integrated procedures for identifying, reporting and explaining data errors or weaknesses in data integrity via exceptions reports.
Principle 8 Comprehensiveness – Risk management reports should cover all material risk areas within the organisation. The depth and scope of these reports should be consistent with the size and complexity of the bank’s operations and risk profile, as well as the requirements of the recipients….
Risk management reports should include exposure and position information for all significant risk areas (eg credit risk, market risk, liquidity risk, operational risk) and all significant components of those risk areas (eg single name, country and industry sector for
credit risk). Risk management reports should also cover risk-related measures (eg regulatory and economic capital).
You have heard Willie Sutton’s answer to: “Why do you rob banks, Mr. Sutton?”, Answer: “Because that’s where the money is.”
Same answer for: “Why write topic maps for banks?”
I first saw this at Basel Committee issues “Principles for effective risk data aggregation and risk reporting – final document” by Ken O’Connor.