Basic Understanding of Big Data. What is this and How it is going to solve complex problems by Deepak Kumar.
From the post:
Before going into details about what is big data let’s take a moment to look at the below slides by Hewlett-Packard.
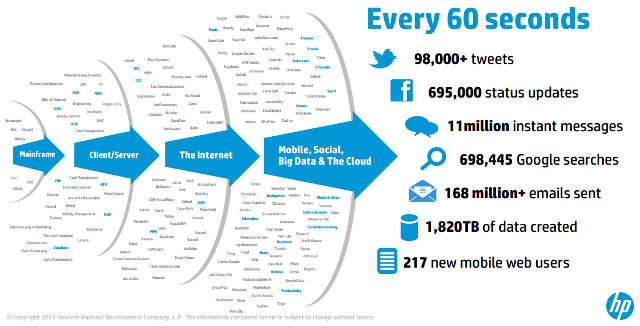
The post goes on to describe big data but never quite reaches saying how it will solve complex problems.
I mention it for the HP graphic that illustrates the problem of big data for the intelligence community.
Yes, they have big data as in the three V’s: volume, variety, velocity and so need processing infrastructure to manage that as input.
However, the results they seek are not the product of summing clicks, likes, retweets, ratings and/or web browsing behavior, at least not for the most part.
The vast majority of the “big data” at their disposal is noise that is masking a few signals that they wish to detect.
I mention that because of the seeming emphasis of late on real time or interactive processing of large quantities of data, which isn’t a bad thing, but also not a useful thing when what you really want are the emails, phone contacts and other digital debris of say < one thousand (1,000) people (that number was randomly chosen as an illustration, I have no idea of the actual number of people being monitored). It may help to think of big data in the intelligence community as consisting of a vast amount of "big data" about which it doesn't care and a relatively tiny bit of data that it cares about a lot. The problem being one of separating the data into those two categories. Take the telephone metadata records as an example. There is some known set of phone numbers that are monitored and contacts to and from those numbers. The rest of the numbers and their data are of interest if and only if at some future date they are added to the known set of phone numbers to be monitored. When the monitored numbers and their metadata are filtered out, I assume that previously investigated numbers for pizza delivery, dry cleaning and the like are filtered from the current data, leaving only current high value contacts or new unknowns for investigation. An emphasis on filtering before querying big data would reduce the number of spurious connections simply because a smaller data set has less random data that could be seen as patterns with other data. Not to mention that the smaller the data set, more prior data could be associated with current data without overwhelming the analyst. You may start off with big data but the goal is a very small amount of actionable data.