From the post:
Recently at the AMP Lab, we’ve been focused on building application frameworks on top of the BDAS stack. Projects like GraphX, MLlib/MLI, Shark, and BlinkDB have leveraged the lower layers of the stack to provide interactive analytics at unprecedented scale across a variety of application domains. One of the projects that we have focused on over the last several months we have been calling “ML Pipelines”, an extension of our earlier work on MLlib and is a component of MLbase.
In real-world applications – both academic and industrial – use of a machine learning algorithm is only one component of a predictive analytic workflow. Pre-processing steps and considerations about production deployment must also be taken into account. For example, in text classification, preprocessing steps like n-gram extraction, and TF-IDF feature weighting are often necessary before training of a classification model like an SVM. When it comes time to deploy the model, your system must not only know the SVM weights to apply to input features, but also how to get your raw data into the same format that the model is trained on.
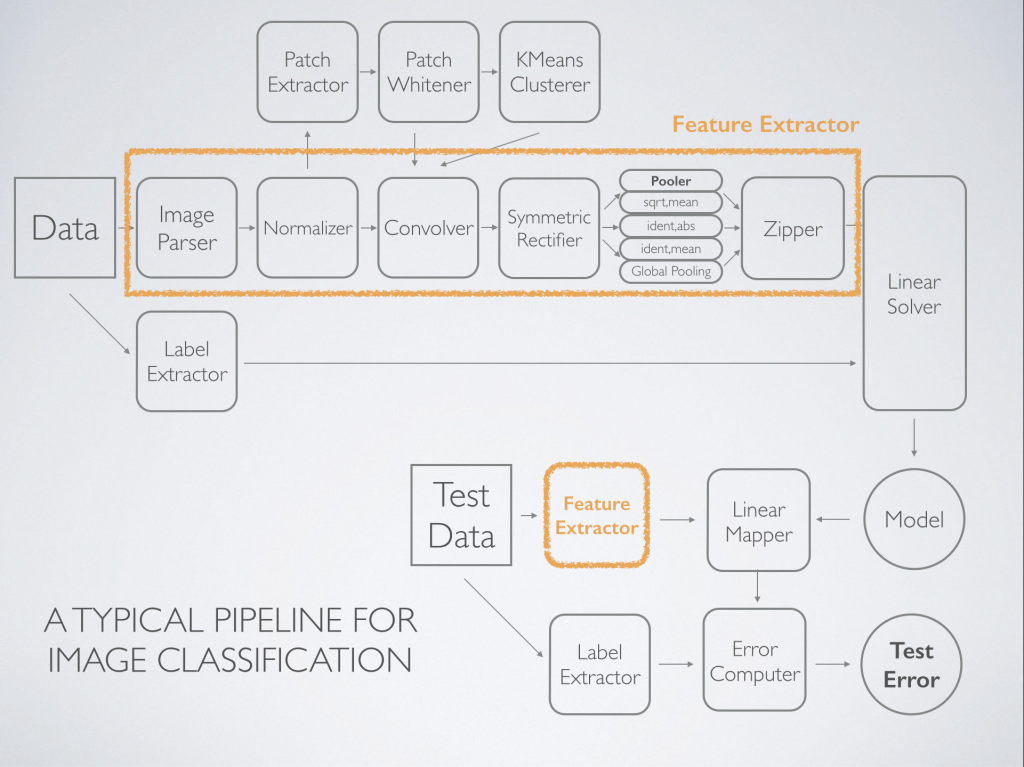
The simple example above is typical of a task like text categorization, but let’s take a look at a typical pipeline for image classification:
This more complicated pipeline, inspired by this paper, is representative of what is done commonly done in practice. More examples can be found in this paper. The pipeline consists of several components. First, relevant features are identified after whitening via K-means. Next, featurization of the input images happens via convolution, rectification, and summarization via pooling. Then, the data is in a format ready to be used by a machine learning algorithm – in this case a simple (but extremely fast) linear solver. Finally, we can apply the model to held-out data to evaluate its effectiveness.
…
Inspirational isn’t it?
Certainly a project to watch for machine learning in particular but also for data processing pipelines in general.
I first saw this in a tweet by Peter Bailis.