Putting Spark to Use: Fast In-Memory Computing for Your Big Data Applications by Justin Kestelyn.
From the post:
Apache Hadoop has revolutionized big data processing, enabling users to store and process huge amounts of data at very low costs. MapReduce has proven to be an ideal platform to implement complex batch applications as diverse as sifting through system logs, running ETL, computing web indexes, and powering personal recommendation systems. However, its reliance on persistent storage to provide fault tolerance and its one-pass computation model make MapReduce a poor fit for low-latency applications and iterative computations, such as machine learning and graph algorithms.
Apache Spark addresses these limitations by generalizing the MapReduce computation model, while dramatically improving performance and ease of use.
Fast and Easy Big Data Processing with Spark
At its core, Spark provides a general programming model that enables developers to write application by composing arbitrary operators, such as mappers, reducers, joins, group-bys, and filters. This composition makes it easy to express a wide array of computations, including iterative machine learning, streaming, complex queries, and batch.
In addition, Spark keeps track of the data that each of the operators produces, and enables applications to reliably store this data in memory. This is the key to Spark’s performance, as it allows applications to avoid costly disk accesses. As illustrated in the figure below, this feature enables:
…
I would not use the following example to promote Spark:
One of Spark’s most useful features is the interactive shell, bringing Spark’s capabilities to the user immediately – no IDE and code compilation required. The shell can be used as the primary tool for exploring data interactively, or as means to test portions of an application you’re developing.
The screenshot below shows a Spark Python shell in which the user loads a file and then counts the number of lines that contain “Holiday”.
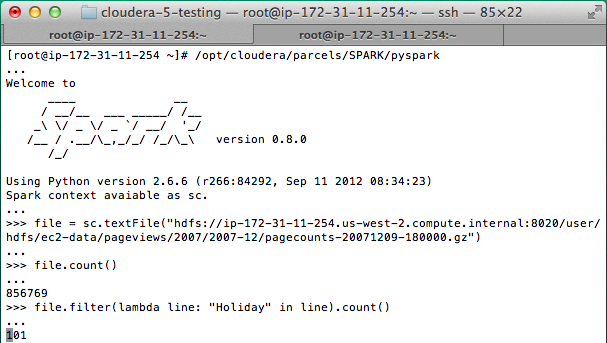
Isn’t that just:
grep holiday WarAndPeace.txt | wc -l
15
?
Grep doesn’t require an IDE or compilation either. Of course, grep isn’t reading from an HDFS file.
The “file.filter(lamda line: “Holiday” in.line).count()” works but some of us prefer the terseness of Unix.
Unix text tools for HDFS?