in the dark heart of a language model lies madness…. by Chris.
From the post:
This is the second in a series of post detailing experiments with the Java Graphical Authorship Attribution Program. The first post is here.
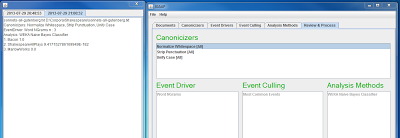
In my first run (seen above), I asked JGAAP to normalize for white space, strip punctuation, turn everything into lowercase. Then I had it run a Naive Bayes classifier on the top 50 tri-grams from the three known authors (Shakespeare, Marlowe, Bacon) and one unknown author (Shakespeare’s sonnets).
Based on that sample, JGAAP came to the conclusion that Francis Bacon wrote the sonnets. We know that because it lists its guesses in order from best to worst in the left window in the above image. Bacon is on top. This alone is cause to start tinkering with the model, but the results didn’t look as flat weird until I looked at the image again today. It lists the probability that the sonnets were written by Bacon as 1. A probability of 1 typically means absolute certainty. So this model, given the top 50 trigrams, is absolutely certain that Francis Bacon wrote those sonnets … Bullshit. A probabilistic model is never absolutely certain of anything. That’s what makes it probabilistic, right?
So where’s the bug? Turns out, it might have been poor data management on my part. I didn’t bother to sample in any kind of fair and reasonable way. Here are my corpora:
(…)
You may not be a stakeholder in the Shakespeare vs. Bacon debate, but you are likely to encounter questions about the authorship of data. Particularly text data.
The tool that Chris describes is a great introduction to that type of analysis.