I haven’t finished documenting the issues I encountered with SQLFairy in parsing the MediaWiki schema but I was able to create a png diagram of the schema.
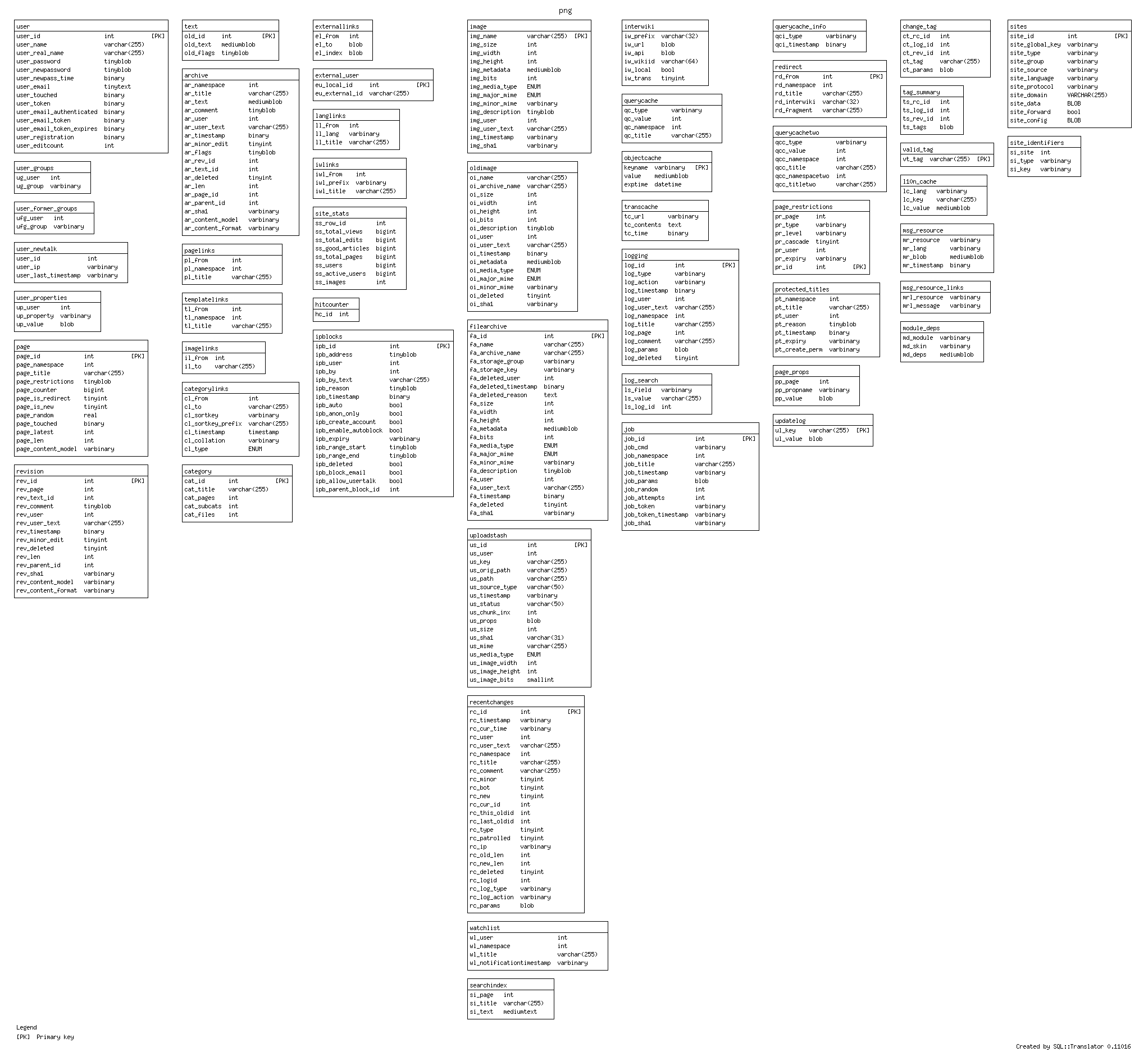{kind=link}
Should be easier than reading the schema but otherwise I’m not all that impressed.
Some modeling issues to note up front.
SQL Identifiers:
The INT datatype in MySQL is defined as:
| Type | Storage | Minimum Value | Maximum Value |
| INT | 4 | -2147483648 | 2147483647 |
Whereas, the XML syntax for topic maps defines the item identifiers datatype as xsd:ID.
XSD:ID is defined as:
The type xsd:ID is used for an attribute that uniquely identifies an element in an XML document. An xsd:ID value must be an xsd:NCName. This means that it must start with a letter or underscore, and can only contain letters, digits, underscores, hyphens, and periods.
Opps! “[M]ust start with a letter or underscore….”
That leaves out all the INT type IDs that you find in SQL databases.
And it rules out all identifiers that don’t start with a letter or underscore.
One good reason to have an alternative (to XML) syntax for topic maps. The name limitation arose more than twenty years ago and should not trouble us now.
SQL Tables/Rows
Wikipedia summarizes relational database tables in part as: http://en.wikipedia.org/wiki/Relation_(database)
A relation is defined as a set of tuples that have the same attributes. A tuple usually represents an object and information about that object. Objects are typically physical objects or concepts. A relation is usually described as a table, which is organized into rows and columns. All the data referenced by an attribute are in the same domain and conform to the same constraints….
As the articles notes: “A tuple usually represents an object and information about that object.” (Read subject for object.)
Converting a database to a topic map begins with deciding what subject every row of each table represents. And recording what information has been captured for each subject.
As you work through the MediaWiki tables, ask yourself what information about a subject must be matched for it to be the same subject?
Normalization
From Wikipedia:
Normalization was first proposed by Codd as an integral part of the relational model. It encompasses a set of procedures designed to eliminate nonsimple domains (non-atomic values) and the redundancy (duplication) of data, which in turn prevents data manipulation anomalies and loss of data integrity. The most common forms of normalization applied to databases are called the normal forms.
True enough but the article glosses over the shortfall of then current databases to handle “non-atomic values” and to lack the performance to tolerate duplication of data.
I say “…then current databases…” but the limitations of “non-atomic values” and non-duplication of data persist to this day. Normalization, an activity by the user, is meant to compensate for poor hardware/software performance.
From a topic map perspective, normalization means you will find data about a subject in more than one table.
Next Week
I will start with the “user” table in MediaWiki-1.21.1-tables.sql next Monday.
Question: Which other tables, if any, should we look at while modeling the subject from rows in the user table?